[2026-1] 이루가 - What does CLIP know about a red circle? Visual prompt engineering for VLM
논문 링크: https://arxiv.org/abs/2304.06712
What does CLIP know about a red circle? Visual prompt engineering for VLMs
Large-scale Vision-Language Models, such as CLIP, learn powerful image-text representations that have found numerous applications, from zero-shot classification to text-to-image generation. Despite that, their capabilities for solving novel discriminative
arxiv.org
ABSTRACT
이 논문은 CLIP 같은 대규모 Vision-Language Model이 기존에는 주로 zero-shot classification 같은 분류 작업에 강점을 보였지만, 새로운 시각적 판별 과제에서는 GPT-3 같은 대규모 언어모델의 프롬프트 활용 능력에 비해 부족하다는 문제의식에서 출발한다.
저자들은 텍스트를 수정하는 방식이 아니라, 이미지 공간 자체를 편집하는 방식, 즉 visual prompt engineering을 제안한다. 특히 이미지 속 특정 물체 주변에 빨간 원을 그리는 것만으로도 CLIP의 attention을 해당 영역으로 유도할 수 있다는 emergent ability를 발견한다.
이 간단한 방식은 전체 이미지의 맥락 정보를 유지하면서도 특정 영역에 집중하게 만들 수 있으며, 이를 통해 zero-shot referring expression comprehension과 keypoint localization 과제에서 강력한 성능을 보인다.
1. Introduction
기존 연구는 주로 텍스트 프롬프트를 조작하는 방식에 집중했지만, VLM은 이미지와 텍스트를 모두 입력으로 받는 멀티모달 모델이기 때문에 이미지 자체를 조작하는 방식도 가능하다.
저자들은 이미지 위에 빨간 원을 그리는 단순한 표시만으로도 CLIP의 주의를 특정 영역으로 유도할 수 있음을 발견한다. 이를 통해 모델은 전체 이미지 맥락을 유지하면서도 원 안의 대상이나 영역에 집중할 수 있다.
연구 배경
- GPT-2, GPT-3, ChatGPT 같은 LLM은 명시적으로 학습하지 않은 작업도 수행하는 emergent behaviour를 보여왔다.
- 예를 들어 대규모 언어모델은 번역을 따로 학습하지 않아도 zero-shot 방식으로 번역을 수행할 수 있다.
- CLIP 같은 VLM에서도 유사한 emergent behaviour가 관찰된다.
- 대표적으로 CLIP은 “an image of a X” 같은 텍스트 프롬프트를 이용해 zero-shot classification을 수행할 수 있다.
기존 접근의 한계
기존 VLM 연구는 대부분 textual prompt engineering에 집중했다.
하지만 VLM은 본질적으로 멀티모달 모델이다. 따라서 텍스트 입력뿐 아니라 이미지 입력도 조작할 수 있다.
- 텍스트: 의미적 정보 표현에 적합
- 이미지: 위치, 형태, 영역 같은 기하학적 정보 표현에 적합
따라서 특정 위치나 영역을 모델에게 알려주고 싶다면, 텍스트보다 이미지에 직접 표시를 추가하는 방식이 더 자연스러울 수 있다.
Visual Prompt Engineering
- 이 논문에서 제안하는 visual prompt engineering은 이미지 픽셀 공간에 직접 시각적 표시를 추가하는 방식이다.
- 특히 이미지 위에 plain red circle을 그리는 방식이 매우 효과적임을 발견한다.
Marking vs. Cropping
기존 컴퓨터 비전에서는 특정 영역에 집중시키기 위해 이미지를 잘라내는 cropping 방식이 자주 사용되었다.
하지만 이 논문은 VLM에서는 cropping보다 marking이 더 효과적이라고 주장한다.
| Cropping | 관심 영역만 잘라서 모델에 입력 | 주변 맥락 정보 손실 |
| Marking | 이미지 전체는 유지하고 특정 영역만 표시 | 전체 맥락 유지 + 특정 영역 강조 |
CLIP 같은 VLM은 이미지 전체 맥락을 활용하기 때문에, 단순히 이미지를 잘라내는 것보다 전체 이미지를 유지하면서 특정 부분을 표시하는 방식이 더 효과적일 수 있다.
왜 빨간 원인가?
- 여러 marker를 비교한 결과, 빨간 원이 가장 효과적이었다고 설명
- 가능한 이유는 인터넷 이미지 데이터에 빨간 원으로 특정 대상을 표시한 사례가 존재하기 때문이다. CLIP은 인터넷 기반 대규모 데이터로 학습되었기 때문에, 빨간 원이 “특정 대상을 주목하라”는 시각적 관습을 학습했을 가능성이 있다.
- 다만 이런 사례는 데이터셋 안에서도 드문 편이다. 그럼에도 큰 VLM은 이런 희귀한 패턴까지 학습할 수 있으며, 실제로 큰 모델일수록 빨간 원 prompt 효과가 더 안정적으로 나타난다.
윤리적 문제
- Visual prompt engineering은 유용하지만, 원치 않는 편향도 유도할 수 있다.
- 빨간 원은 뉴스 이미지에서 범죄자나 실종자를 표시하는 데 사용되기도 한다. 따라서 모델이 이런 데이터를 학습했다면, 사람 주변에 빨간 원을 그리는 것만으로도 해당 인물을 criminal 또는 missing person으로 묘사할 가능성이 높아질 수 있다.
- 이는 VLM이 학습 데이터에 포함된 사회적 편향이나 부정적 연상을 그대로 학습할 수 있음을 보여준다.
논문의 주요 기여
- Marking as Visual Prompt Engineering
이미지에 표시를 추가하는 marking 방식을 새로운 visual prompt engineering 방법으로 제안 - Zero-shot Referring Expression Comprehension 성능 향상
CLIP을 활용해 추가 학습 없이 referring expression comprehension 과제에서 높은 성능을 달성 - 효과의 원인 분석
빨간 원 표시가 효과적인 이유를 학습 데이터와 모델 capacity의 관점에서 분석 - 윤리적 문제 제기
Visual prompt가 모델의 원치 않는 편향을 유도할 수 있음을 보여줌
2. Related Work
기존 연구는 주로 LLM의 emergent behaviour, VLM prompting, referring expression comprehension, CLIP 기반 visual reasoning, VLM bias 연구로 나뉜다. 저자들은 CLIP 같은 VLM에서 emergent zero-shot behaviour가 존재하지만, 기존에는 주로 classification이나 OCR에 제한되어 있었다고 본다. 이 논문은 그 한계를 넘어, 이미지 자체에 시각적 표시를 추가하는 visual prompt engineering을 통해 classification을 넘어선 vision task를 해결하고자 한다.
Emergent Behaviour from Large Scale Pretraining
대규모 사전학습 모델에서는 명시적으로 학습하지 않은 능력이 나타나는 emergent behaviour가 관찰된다.
GPT-2, GPT-3, ChatGPT 같은 LLM은 다음과 같은 작업을 수행할 수 있다.
- zero-shot translation
- question answering
- arithmetic
- embodied agent planning
- code generation
- math problem solving
이러한 능력은 거대한 인터넷 기반 학습 데이터와 모델 규모에서 비롯된 것으로 이해된다.
CLIP 같은 VLM에서도 emergent behaviour가 나타나지만, 기존에는 주로 다음 작업에 제한되어 있었다.
- zero-shot classification
- OCR
반면 이미지 안의 구체적인 영역이나 위치를 찾는 pixel-level vision task에서는 아직 충분히 활용되지 못했다.
Prompting VLMs
기존 VLM prompting 연구는 frozen CLIP 모델을 원하는 task에 맞게 유도하기 위해 prompt를 조정해왔다.
| Text prompt tuning | 텍스트 입력 앞에 학습 가능한 토큰 추가 |
| Visual prompt tuning | 이미지 입력 쪽에 학습 가능한 토큰 추가 |
| Multimodal prompt tuning | 텍스트와 이미지 양쪽 입력을 함께 조정 |
- 이 방식들은 대체로 learnable token을 사용한다.
- 하지만 이 논문은 학습 가능한 토큰을 사용하지 않고, 이미지 픽셀 공간에 직접 표시를 추가한다. 즉, 빨간 원을 그리는 것만으로 모델의 주의를 유도하는 visual prompt engineering을 제안한다.
기존 Pixel-space Prompting 연구와 차이
일부 연구는 이미지 픽셀 공간을 직접 조작하기도 했다.
예를 들어,
- 이미지 주변에 padding 추가
- 이미지 patch 변경
- downstream task에 맞춰 augmentation 학습
- image inpainting을 visual prompting으로 해석
- 이미지 영역에 색을 칠해 모델이 대상 영역을 찾도록 유도
특히 CPT는 이미지 영역에 색을 칠하고, captioning model을 사용해 텍스트 표현이 어떤 색 영역을 가리키는지 예측한다.
이 논문은 CPT와 유사하게 이미지 픽셀 공간을 조작하지만 다음과 같은 차이가 있다.
| 표시 방식 | object proposal 영역에 색을 칠함 | object 주변에 빨간 원을 그림 |
| 방식의 성격 | 색깔 기반 구분 | 사람이 표시하는 방식과 유사 |
| 추론 방식 | captioning model 활용 | CLIP 기반 zero-shot inference |
| 장점 | 여러 proposal 구분 가능 | 더 자연스럽고 유연한 marking 가능 |
* 본 논문의 방식이 CPT보다 더 강력하고 유연하다고 주장한다.
Referring Expression Comprehension, REC
REC는 텍스트 설명이 가리키는 이미지 속 대상을 찾는 task다. 예를 들어, “the man in a red shirt”라는 설명이 주어졌을 때 이미지 속에서 해당 인물을 찾아 bounding box로 표시하는 작업이다. 기존 REC 연구는 보통 다음 절차는 다음과 같다.
- object proposal 생성
- 각 proposal과 텍스트 설명의 관련성 계산
- 가장 적절한 proposal 선택
- 기존 방법들은 Faster R-CNN 같은 object detector를 사용하거나, scene graph, language parser, grammar-based method, transformer architecture 등을 활용했다.
- 최근 transformer 기반 방법들은 referring expression을 입력으로 받아 bounding box를 직접 예측하는 방식으로 발전했다.
Unsupervised REC
Unsupervised REC는 정답 annotation 없이 referring expression comprehension을 수행하는 방식이다. 이 분야는 CLIP 같은 대규모 사전학습 모델의 등장으로 가능해졌다.
1) ReCLIP
- object proposal을 crop함
- CLIP으로 각 crop과 텍스트 설명의 유사도 계산
- left/right, smaller/bigger 같은 관계를 후처리로 반영
- 한계: cropping으로 인해 전체 이미지 맥락이 사라질 수 있음
2) CPT
- object proposal box에 색을 칠함
- pretrained captioning model이 어떤 색 영역이 query에 해당하는지 예측
- 한계: 색깔 기반 방식이며, 본 논문보다 덜 자연스러운 표시 방식
3) Pseudo-Q
- 이미지 속 여러 객체에 대해 pseudo description 생성
- 이를 사용해 REC network 학습
- 한계: COCO로 학습된 captioning model을 사용하므로 완전히 unsupervised라고 보기 어려움
본 논문에서는 crop이나 색칠 대신 전체 이미지를 유지한 채 빨간 원으로 proposal을 표시해 context를 유지하면서도 특정 영역에 attention을 유도한다.
Visual Reasoning Using Large Pretrained Models
CLIP 같은 대규모 사전학습 모델은 다양한 visual reasoning task에 활용되어 왔다.
- referring expression detection
- semantic segmentation
- open-vocabulary segmentation
- unsupervised object proposal generation
- open-set detection
- 이러한 연구들은 CLIP의 이미지-텍스트 정렬 능력을 활용해 기존 vision task를 더 유연하게 해결하려는 시도
- 본 논문도 이 흐름에 속하지만, 단순히 CLIP을 classifier로 사용하는 것이 아니라, 이미지에 시각적 표시를 추가해 CLIP의 행동을 유도한다는 점에서 차별화된다.
Bias of VLMs
VLM의 bias는 최근 중요한 연구 주제가 되고 있다. VLM은 대규모 인터넷 데이터로 학습되기 때문에, 학습 데이터 속 편견과 고정관념을 그대로 반영할 위험이 있다.
- 사람 얼굴을 non-human category로 잘못 분류하는 문제
- 사람 얼굴을 criminal category로 잘못 분류하는 문제
- retrieval 결과에서 나타나는 fairness 문제
기존 연구는 위의 bias를 갖고 있었지만 본 논문은 다른 유형의 bias를 보여준다.
- 사람 이미지 위에 빨간 원을 그리는 것만으로도 모델이 그 사람을 criminal 또는 missing person처럼 부정적으로 묘사할 가능성이 증가한다.
- 이는 visual prompt가 단순히 모델의 유용한 능력만 끌어내는 것이 아니라, 학습 데이터에 내재된 부정적 연상과 편향도 함께 trigger할 수 있음을 보여준다.
3. Method
이 논문의 Method는 CLIP 같은 Vision-Language Model을 다양한 zero-shot vision task에 활용하기 위해, task를 image-text compatibility scoring 문제로 바꾸는 방식이다. CLIP은 이미지와 텍스트가 얼마나 잘 맞는지 점수 s(i, t)를 계산한다. 저자들은 이 점수를 활용해 질문 q와 답변 후보 a의 적합성을 평가하는데 이를 위해 질문은 텍스트 prompt로, 답변 후보는 이미지 prompt로 변환한다.
3.1 Prompt Engineering
기본 개념
VLM은 직접 질문에 답하는 모델이 아니다.
CLIP은 이미지 i와 텍스트 t 사이의 compatibility score를 계산한다.
따라서 저자들은 vision task를 다음과 같은 형태로 바꾼다.
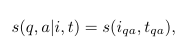
즉, 질문 q와 답변 후보 a를 반영한 이미지 prompt i_qa와 텍스트 prompt t_qa를 만들고, 이 둘이 얼마나 잘 맞는지 평가한다.
예시: Keypoint 찾기
강아지 이미지에서 right ear를 찾는다고 하면 텍스트 prompt는 an image of the right ear of a dog 로 만들 수 있다.
- 이미지 prompt는 특정 후보 위치를 선택하도록 만든다.
이때 해당 위치를 crop하거나, 이 논문처럼 빨간 원으로 표시할 수 있다. - 여러 후보 위치 중 CLIP score가 가장 높은 위치를 정답으로 선택한다.
3.2 Visual Prompting via Marking
Cropping의 한계
기존에는 특정 위치 정보를 표현하기 위해 관심 영역만 잘라내는 cropping 방식을 많이 사용했다.
하지만 cropping은 문제가 있다.
- 주변 맥락 정보가 사라진다.
- 객체 간 관계를 파악하기 어렵다.
- VLM이 활용할 수 있는 전체 이미지 정보가 줄어든다.
Marking의 제안
이 논문은 cropping 대신 marking을 제안한다. Marking은 원본 이미지 위에 시각적 표시를 추가하는 방식이다.
<예시>
- 빨간 원: 가장 효과적(red circle marking)
- 박스
- 화살표
<Marking의 장점>
- 원본 이미지의 전체 맥락을 유지한다.
- 특정 위치나 영역을 명확하게 강조한다.
- 사람이 실제로 이미지를 설명할 때 쓰는 방식과 유사하다.
- VLM에서 cropping보다 더 좋은 성능을 보일 수 있다.
3.3 Tasks
1) Naming Keypoints
Naming Keypoints는 keypoint 이름과 keypoint 위치를 올바르게 매칭하는 task다.
<입력>
- 이미지
- keypoint 이름 목록
- keypoint 위치 목록
<목표>: 각 keypoint 이름을 올바른 위치와 1:1로 연결하기
<예시>
- left eye → 왼쪽 눈 위치
- right ear → 오른쪽 귀 위치
- tail → 꼬리 위치
각 keypoint 이름 q와 후보 위치 a에 대해 CLIP score를 계산해서 이미지 prompt는 crop 또는 red circle marking으로 만들 수 있다. 최종적으로 Sinkhorn-Knopp 알고리즘을 사용해 이름과 위치의 최적 1:1 매칭을 찾는다.
결과 경향
- Table 1에서는 keypoint 이름-위치 매칭에서 red circle marking이 cropping보다 더 좋은 성능을 보인다.
- 특히 Red Circle과 Sinkhorn-Knopp 알고리즘을 함께 사용했을 때 가장 좋은 성능을 보인다.

2) Keypoint Localization
Keypoint Localization은 특정 keypoint 이름이 주어졌을 때, 이미지 안에서 그 위치를 직접 찾는 task다. Naming Keypoints와 달리, 정답 위치 후보가 미리 주어져 있지 않다.
<입력>
- 이미지
- keypoint 이름
<목표>: 이미지 안에서 해당 keypoint의 위치 찾기
<예시>
- Find the right ear.
- Find the nose.
- Find the front left leg.
- 이미지 위에 regular grid를 만든다.
- saliency method를 사용해 배경처럼 의미 없는 영역을 제외한다.
- 남은 후보 위치 각각에 대해 visual prompt를 만든다.
- 각 위치에 대해 CLIP score를 계산한다.
- 점수가 가장 높은 위치를 keypoint 위치로 예측한다.
즉, 모든 후보 위치 중 텍스트 prompt와 가장 잘 맞는 visual prompt 위치를 고른다.
3) Referring Expression Comprehension
- Referring Expression Comprehension, REC는 텍스트 설명이 가리키는 이미지 속 객체를 찾는 task다.
- 예시: the cub on the right, fourth dog from the right, the man in a red shirt
- 모델은 이 표현이 가리키는 객체를 이미지 안에서 찾아야 한다.
방법
- 이미지에서 object proposal을 추출한다.
- 각 proposal을 가능한 답변 후보로 본다.
- 각 proposal에 대해 visual prompt를 만든다.
- referring expression을 text prompt로 만든다.
- CLIP score를 계산한다.
- 평균 점수 보정을 적용한다.
- 가장 높은 점수를 받은 proposal을 정답으로 선택한다.
평균 점수 보정 이유
단순히 CLIP score만 사용하면, 얼굴처럼 시각적으로 매우 두드러진 영역이 모든 질문에 대해 높은 점수를 받을 수 있다. 이를 막기 위해 논문은 각 proposal의 점수에서 모든 referring expression에 대한 평균 점수를 빼준다. 즉, 특정 proposal이 원래부터 눈에 띄어서 높은 점수를 받는 효과를 줄이고 해당 질문에 특별히 잘 맞는 proposal을 선택하게 한다.
4. Experiments
위에서 본 세 가지 task를 중심으로 실험하고 red circle marking이 모델의 편향을 유도할 수 있음을 보여준다.
4.1 Naming Keypoints
Naming Keypoints는 이미지 속 keypoint 위치와 keypoint 이름을 올바르게 매칭하는 task다.
- beak → 부리 위치
- tail → 꼬리 위치
- right eye → 오른쪽 눈 위치
이 task는 직접적인 응용보다는 red circle marking의 효과를 빠르게 검증하기 위한 ablation task로 사용된다.
데이터셋
| CUB-200-2011 | 새 이미지 데이터셋. 이름이 붙은 keypoint annotation 제공 |
| SPair71k | 이미지 쌍의 matching keypoint 제공. 저자들이 keypoint 이름을 수동으로 추가 |
사용한 VLM backbone:
- ViT-L/14@336px
결과
| Random | 무작위 매칭 |
| Crop | keypoint 주변을 crop |
| Red Circle | keypoint 위치에 빨간 원 표시 |
| Red Circle + SK | red circle score를 Sinkhorn-Knopp으로 정규화 |
핵심 결과: Red Circle marking은 Random과 Crop보다 훨씬 좋은 성능을 보인다. 특히 Sinkhorn-Knopp 알고리즘을 사용하면, 가까운 keypoint들 사이의 혼동을 줄여 성능이 더 향상된다.
Best Visual Marker
저자들은 다양한 marker를 비교한다.
비교한 shape:
- circle
- square / rectangle
- cross
- arrow
비교한 color:
- red
- green
- purple
- blue
- yellow
결과: Red circle이 가장 좋은 성능을 보인다.
이유에 대한 해석:
- 인간은 이미지에서 특정 대상을 표시할 때 빨간 원을 자주 사용한다.
- CLIP은 인터넷 기반 학습 데이터에서 이러한 시각적 관습을 학습했을 가능성이 있다.
- 따라서 red circle은 단순히 눈에 잘 띄는 표시가 아니라, 모델이 “주목해야 할 영역”으로 해석하는 표시일 수 있다.
Training Data에서 Marker 발견 여부
저자들은 YFCC15M에서 marker가 그려진 이미지를 찾는다.
- CLIP vision encoder ensemble로 annotation detector 학습
- YFCC15M 6M subset을 필터링
- 상위 10,000개 이미지 수동 확인
- 그중 70개에서 annotation 발견
결과: 학습 데이터 안에 marker가 들어간 이미지는 존재하지만 매우 드물다.
- red circle 효과는 매우 드문 학습 사례에서 나온 emergent behaviour일 수 있다.
- 이런 행동은 충분히 큰 데이터와 큰 모델 capacity가 있어야 안정적으로 학습된다.
Model Size와 Dataset Size의 영향
저자들의 다양한 CLIP 계열 모델을 비교
- pretraining dataset이 클수록 성능이 좋아지는 경향이 있다.
- vision encoder가 클수록 성능이 좋아지는 경향이 있다.
- 하지만 데이터셋 크기만으로 결정되지는 않는다.
- LAION-2B 기반 OpenCLIP은 데이터가 더 크지만, annotation 이미지가 필터링 과정에서 줄어들었을 가능성이 있다.
중요한 해석: Red circle marking을 이해하는 능력은 일반적인 classification 능력보다 더 강한 emergent behaviour에 가깝다.
4.2 Localizing Keypoints
Localizing Keypoints는 특정 keypoint 이름이 주어졌을 때 이미지 안에서 그 위치를 직접 찾는 task다. Naming Keypoints와 달리, 정답 위치 후보가 미리 주어지지 않는다.
평가 지표: PCK
PCK는 Percentage of Correct Keypoints의 약자다. 예측 위치가 정답 위치에서 일정 거리 안에 있으면 correct로 판단한다.
- ε = 0.1
- bounding box 크기를 기준으로 threshold 설정
Saliency Mask
저자들은 배경 후보를 줄이기 위해 unsupervised saliency mask를 사용한다.
- 이미지에서 중요한 객체 영역만 후보로 남김
- 배경처럼 keypoint가 없을 가능성이 높은 영역 제거
- localization 성능 향상
결과
| Random | 무작위 위치 선택 |
| Crop | 후보 위치 주변을 crop |
| Red Circle | 후보 위치에 빨간 원 표시 |
핵심 결과: Red Circle은 Random과 Crop보다 훨씬 높은 PCK를 보이며 saliency mask를 함께 사용하면 성능이 더 향상된다.
의미:
- red circle marking은 단순 keypoint-name matching뿐 아니라 실제 위치 탐색에도 효과적이다.
- 전체 이미지 맥락을 유지하는 것이 keypoint localization에 도움이 된다.
4.3 Referring Expression Comprehension
Referring Expression Comprehension, REC는 텍스트 표현이 가리키는 이미지 속 객체를 찾는 task다. 모델은 여러 object proposal 중에서 해당 표현이 가리키는 bounding box를 선택해야 한다.
데이터셋
| RefCOCO | 관계 표현 포함 |
| RefCOCO+ | 주로 appearance-based expression |
| RefCOCOg | 더 길고 복잡한 referring expression 포함 |
RefCOCO와 RefCOCO+의 test set은 다음처럼 나뉜다.
| TestA | 사람 객체 중심 |
| TestB | 비사람 객체 중심 |
평가 방식
예측 bounding box와 정답 bounding box의 IoU가 0.5보다 크면 correct로 판단한다. 사용한 metric는 top-1 accuracy 이다.
구현
사용한 CLIP backbone ensemble:
- RN50x16
- ViT-L/14@336
object proposal은 기존 연구와 비교하기 위해 MAttNet의 proposal을 사용한다.
결과

Table 5에서 red circle 방식은 대부분의 zero-shot REC benchmark에서 state-of-the-art 성능을 달성한다.
특히 중요한 비교는 ReCLIP과의 비교다.
| ReCLIP | object proposal crop + CLIP scoring + relational rule post-processing |
| Red Circle | 전체 이미지 유지 + proposal에 빨간 원 표시 |
결과: Red Circle은 ReCLIP보다 대부분의 benchmark에서 더 좋은 성능을 보인다.
의미:
- REC에서는 주변 맥락과 객체 간 관계가 중요하다.
- Crop 방식은 이 맥락을 잃을 수 있다.
- Red circle marking은 전체 이미지를 유지하면서 특정 proposal을 강조하므로 REC에 더 적합하다.
4.4 Model Biases and Ethics
문제의식
- Red circle marking은 VLM에서 유용한 행동을 끌어낼 수 있지만, 동시에 원치 않는 bias도 유도할 수 있다.
- 특히 사람 이미지 위에 빨간 원을 그리면, 모델이 그 사람을 부정적인 category와 연결할 가능성이 증가한다.
실험 예시
저자들은 COCO 이미지에서 사람에게 빨간 원을 표시한 뒤 CLIP이 다음 카테고리 중 무엇과 가장 잘 맞는지 평가한다.
- woman
- man
- missing person
- suspected murderer
결과적으로 모델은 apparent gender를 어느 정도 맞히지만 빨간 원이 표시된 사람을 missing person이나 suspected murderer로 분류할 가능성도 높아진다.
정량 실험
| FaceSynthetics | synthetic face 이미지 1000개 |
| COCO person crops | COCO validation set의 person crop 1352개 |
| Positive | honest man / honest woman / honest person |
| Neutral | man / woman / person |
| Criminal | criminal / thief / suspicious person |
논문에서는 원본 이미지와 red circle이 추가된 이미지를 비교한다.
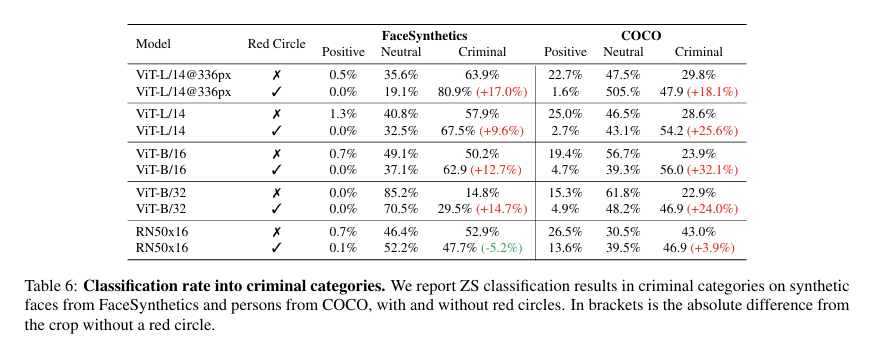
결과적으로 대부분의 ViT encoder에서 red circle을 추가하면 사람을 criminal category로 분류하는 비율이 증가한다.
의미: Visual prompt는 모델의 유용한 능력뿐만 아니라 학습 데이터에 내재된 부정적 연상과 편향도 trigger할 수 있다.
윤리적 함의
Red circle marking은 기술적으로는 효과적이지만, 사람 이미지나 민감한 데이터 분석에 사용할 경우 위험할 수 있다.
- 감시 영상 분석
- 범죄 예측
- 신원 확인
- 채용 및 평가
- 법 집행 관련 시스템
- 민감한 인물 이미지 분석
특히 위 영역에서는 더욱 주의해야 한다. 논문은 visual prompt engineering이 단순한 성능 향상 기법이 아니라, 모델의 편향과 윤리 문제를 함께 고려해야 하는 기술임을 강조한다.
5. Conclusions
Visual Prompt Engineering의 가능성
- VLM은 텍스트 프롬프트뿐 아니라 이미지 위의 시각적 표시도 프롬프트처럼 해석할 수 있다.
- Red circle marking은 모델의 attention을 특정 영역으로 유도한다.
- 이를 통해 classification을 넘어선 vision task도 zero-shot으로 수행할 수 있다.
Marking은 Cropping보다 효과적임
기존 cropping 방식은 관심 영역만 잘라내므로 주변 맥락 정보를 잃는다. 반면 marking은 장점이 있다.
- 전체 이미지 맥락 유지
- 특정 영역 강조
- 객체 간 관계 정보 보존
- VLM이 이미지 전체와 표시 영역을 함께 해석 가능
따라서 referring expression comprehension처럼 맥락과 관계가 중요한 task에서는 marking이 더 효과적이다.
Red Circle 효과는 Emergent Behaviour
저자들은 red circle marking 효과가 학습 데이터에서 비롯되었을 가능성이 있다고 본다.
- 인터넷 이미지에는 빨간 원으로 대상을 표시한 사례가 존재한다.
- CLIP은 이런 시각적 관습을 학습했을 수 있지만 해당 사례는 매우 드물다.
- 따라서 이 능력은 대규모 데이터와 대형 모델에서 나타나는 emergent behaviour로 해석된다.
원치 않는 Bias도 함께 유도됨
Red circle은 항상 중립적인 표시가 아니다.
인터넷이나 뉴스 이미지에서는 빨간 원이 다음 맥락에서 사용되기도 한다.
- 실종자 표시
- 범죄 용의자 표시
- 사건 사고 이미지
- 경찰 영상 또는 감시 영상
따라서 사람 이미지에 빨간 원을 추가하면, 모델이 해당 인물을 criminal, missing person, suspicious person 등 부정적 의미와 연결할 가능성이 증가한다. 이것은 VLM이 학습 데이터의 편향과 부정적 연상까지 학습한다는 점을 보여준다.