[2026-1] 정유림 - DataComp: In search of the next generation of multimodal datasets
논문 : https://arxiv.org/abs/2304.14108
DataComp: In search of the next generation of multimodal datasets
Multimodal datasets are a critical component in recent breakthroughs such as Stable Diffusion and GPT-4, yet their design does not receive the same research attention as model architectures or training algorithms. To address this shortcoming in the ML ecos
arxiv.org
보통 머신러닝 benchmark는 데이터셋을 고정하고 모델 구조나 학습법을 변경.
DataComp는 반대로 모델 구조, 학습 코드, compute budget을 고정하고, 연구자들이 어떤 데이터를 고를지를 바꾸게 만든 benchmark
- 논문의 문제의식
CLIP, DALL-E, Stable Diffusion, Flamingo, GPT-4 같은 multimodal model들은 서로 다른 학습 방식을 쓰지만 공통적으로 대규모 image-text pair 데이터셋에 의존 문제는, 모델 구조나 loss function에 대한 ablation은 많지만 데이터셋 설계 자체는 충분히 연구되지 않았다는 것 많은 SOTA 데이터셋은 비공개이고, 공개 데이터셋인 LAION-2B조차도 data source나 filtering technique이 최종 모델에 어떤 영향을 주는지 명확히 알기 어렵다고 지적 - DataComp가 제안하는 해결책
DataComp는 multimodal dataset design을 위한 benchmark
training code와 compute budget을 고정하고 참가자들이 새로운 training set을 제안
그 training set으로 CLIP을 학습한 뒤, 38개 classification/retrieval task에서 평가
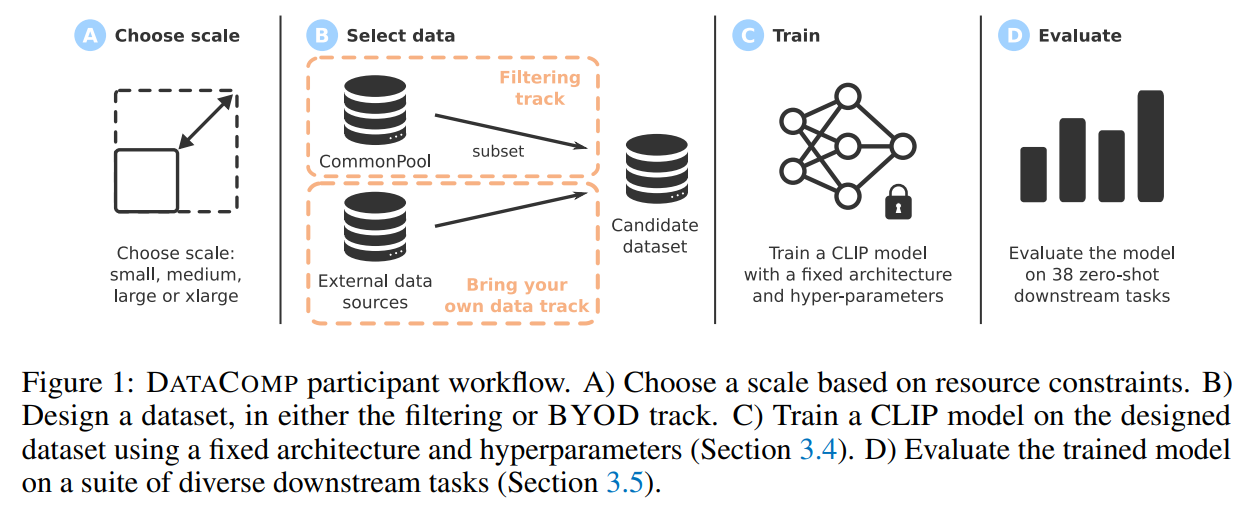
Figure 1 : DataComp 참가자가 따라야 하는 workflow
A. Choose scale
먼저 자원에 맞는 scale을 고릅니다.
자원이 적은 연구자도 small scale에서 참여할 수 있고, 자원이 많은 그룹은 xlarge scale에서 scaling trend를 볼 수 있다.

Table 2 설명: DataComp의 scale 구성
Table 2는 DataComp가 여러 compute scale을 제공한다는 것을 보여줌.
B. Select data
두 번째 단계는 데이터를 고르는 것입니다. 여기에는 두 track이 있습니다.
- Filtering track : Filtering track에서는 CommonPool이라는 거대한 후보군에서 어떤 image-text pair를 남길지 결정
- BYOD track : BYOD track에서는 참가자가 외부 데이터를 가져올 수 있습니다. 단, 평가 testbed와 overlap되면 안됨.
C. Train
세 번째 단계는 선택한 데이터셋으로 CLIP을 학습 여기서 중요한 조건은 fixed architecture and hyperparameters
총 training samples seen을 고정. 작은 데이터셋이라고 학습량이 적어지는 것이 아니라, 더 여러 번 반복해서 학습 → 그래서 DataComp는 데이터셋 크기 자체보다 선택한 데이터의 품질을 비교할 수 있음.
D. Evaluate
마지막 단계는 학습된 CLIP 모델을 여러 downstream task에서 평가하는 것 ImageNet, ImageNetV2, DTD, EuroSAT, SUN-397, MSCOCO 등을 포함한 38개 classification 및 retrieval task로 평가 즉 특정 데이터셋 하나에서만 좋은지 보는 것이 아니라, 다양한 일반화 성능을 확인.
Baselines 핵심 정리
DataComp에서 비교 기준으로 사용한 기본 필터링 방법들을 설명
Filtering baselines
Filtering track에서는 총 6가지 단순한 filtering method를 실험. → 같은 CommonPool에서 어떤 image-text pair를 골라야 CLIP 학습이 잘 되는가?를 확인
1. No filtering
CommonPool 전체를 그대로 사용하는 가장 단순한 baseline.
2. Random subsets
두 번째는 무작위 subset.CommonPool에서 랜덤하게 일부만 고름.
논문에서는 pool의 1%, 10%, 25%, 50%, 75%를 랜덤선택.
작은 subset을 여러 번 반복해서 학습하는 것과, 큰 dataset을 한 번 보는 것이 어떻게 다른지 볼 수 있게됨.
3. Basic filtering
Basic filtering은 사람이 직관적으로 생각할 수 있는 단순 품질 필터.
논문에서는 다음 기준들을 사용함.
필터 의미
| Language filtering | 영어 caption만 남김. fastText 또는 cld3 사용 |
| Caption length filtering | caption이 너무 짧은 것 제거. 2단어 초과, 5글자 초과 |
| Image size filtering | 이미지 짧은 변이 200px 이상 |
| Aspect ratio filtering | 이미지 가로세로비가 3 미만 |
4. CLIP score and LAION filtering
이 부분이 가장 중요
CLIP score filtering은 image와 text가 서로 잘 맞는지를 CLIP으로 계산한 뒤, similarity score가 일정 threshold 이상인 pair만 남기는 방식
CLIP score가 높은 pair는 image-text alignment가 좋을 가능성이 높다를 가정함.
이 방식은 LAION에서도 사용한 방식.
5. Text-based filtering
Text-based filtering은 caption 내용이 downstream task와 관련 있어 보이는 샘플을 고르는 방식
6. Image-based filtering
Image-based filtering은 caption이 아니라 이미지 내용이 ImageNet class와 시각적으로 겹치는지를 기준으로 샘플을 선택
즉 이미지 임베딩 공간에서 ImageNet 이미지와 가까운 시각적 영역의 샘플을 고르는 방식
Table 3 결과 해석
Table 3은 filtering baseline들의 zero-shot 성능을 scale별로 보여줌.
평가 metric은 다음 범주로 나뉩니다.
Metric 의미
| ImageNet | ImageNet zero-shot accuracy |
| ImageNet dist. shifts | ImageNet-V2, Sketch, A, R 등 분포 변화 benchmark |
| VTAB | 다양한 visual task benchmark |
| Retrieval | Flickr30k, MSCOCO 등 image-text retrieval |
| Average over 38 datasets | 전체 38개 task 평균 |
값은 모두 높을수록 좋음
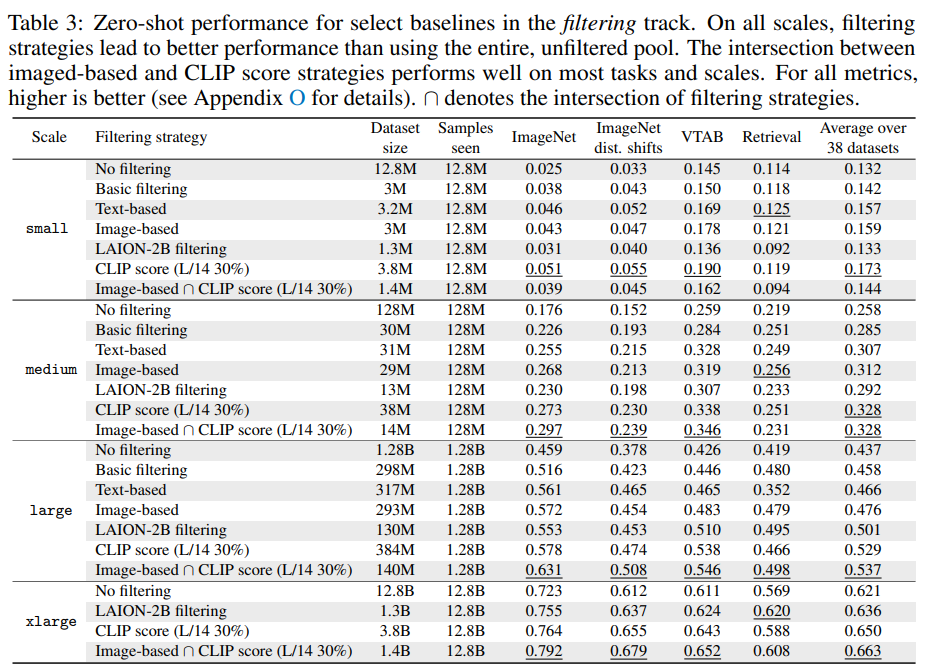
- 핵심 결과 1:
모든 scale에서 filtering이 no filtering보다 좋음. 모든 scale에서 어떤 형태의 filtering이든, 전체 unfiltered pool을 그대로 쓰는 것보다 좋은 성능을 낸다. - 핵심 결과 2: Image-based ∩ CLIP score가 강함 이게 DataComp-1B의 기반이 되는 중요한 baseline
- 핵심 결과 3: 작은 dataset을 여러 번 보는 것이 더 나을 수 있음
ex. xlarge에서 No filtering 12.8B noisy data 1번 보기< Image-based교집합 CLIP score 1.4B filtered data 여러 번 보기 - 핵심 결과 4: CLIP score만으로도 강하지만, 조합하면 더 좋음 CLIP score L/14 30%만 써도 성능이 크게 좋아짐. 하지만, image-based filtering과 교집합을 취하면 더 올라감.
즉, CLIP score는 좋은 alignment filter지만, 시각적 relevance 기준을 추가하면 더 강해질 수 있다는 뜻
Figure 2

: 데이터 다양성과 반복의 trade-off
Figure 2는 subset size를 바꿨을 때 성능이 어떻게 변하는지 보여줍니다.
왼쪽은 ImageNet accuracy, 오른쪽은 38개 dataset 평균 성능입니다.
x축은:학습에 사용한 pool fraction
예를 들어:
0.1 = pool의 10%만 사용 0.3 = pool의 30% 사용 1.0 = pool 전체 사용
- Random subset은 클수록 좋음
Figure 2의 dotted line, 즉 점선은 random subset 무작위로 고르면 subset이 작을수록 좋은 데이터도 많이 빠집니다. 특별히 품질 좋은 sample만 고르는 게 아니기 때문에, 그냥 많이 쓰는 게 나음. - CLIP score filtering은 중간 크기가 가장 좋음
즉 실선은 CLIP score filtering 대략 30%
- 이게 논문에서 말하는 trade off. CLIP score 기준으로 너무 조금만 고르면 데이터가 너무 좁아지고, 너무 많이 고르면 낮은 품질의 sample이 다시 들어옴.
기여 5가지
5.1 Contribution 1: DataComp benchmark
가장 중심 기여는 multimodal dataset design을 위한 benchmark
기존처럼 dataset을 고정하고 모델을 바꾸는 게 아니라, 모델과 compute를 고정하고 training set을 바꾸게 만든 것이 핵심
5.2 Contribution 2: CommonPool
두 번째 기여는 CommonPool입니다.
CommonPool은 Common Crawl에서 수집한 12.8B image-text pair 후보군입니다. 논문은 이를 현재 가장 큰 공개 image-text dataset이라고 설명하고, filtering track에서는 참가자들이 이 CommonPool에서 가장 좋은 subset을 찾는 것이 목표
5.3 Contribution 3: Scaling trends
세 번째 기여는 dataset design에서 scaling trend를 분석할 수 있게 한 것
논문은 filtering approach의 ranking이 scale 전반에서 대체로 일관적이라고 보고.
즉, 작은 scale에서 좋은 filtering 방법이 큰 scale에서도 꽤 잘 작동할 가능성이 있다.
Figure 3:Scale 간 결과가 일관적임
small scale과 medium scale에서 baseline들의 성능이 얼마나 일치하는지 보여줌.
왼쪽은 ImageNet, 오른쪽은 38개 dataset 평균입니다.
각 점은 하나의 filtering baseline입니다.
x축:small scale 성능
y축:medium scale 성능
점들이 우상향으로 놓여 있음.

5.4 Contribution 4: 여러 실험을 통해 잘 고른 작은 데이터가 덜 고른 큰 데이터보다 나음을 확인
네 번째 기여는 여러 실험을 통해 잘 고른 작은 데이터가 덜 고른 큰 데이터보다 나음을 확인했다는점 입니다.
논문은 caption keyword query, image embedding 기반 filtering, CLIP score threshold 등 여러 baseline을 실험했다고 설명합니다. 중요한 결과는 작지만 엄격하게 필터링된 dataset이 같은 pool에서 온 더 큰 dataset보다 더 잘 일반화할 수 있다는 점
더 많은 데이터가 항상 더 좋은 것은 아니다.
잘 고른 작은 데이터가 덜 고른 큰 데이터보다 나을 수 있다.
5.5 Contribution 5: DataComp-1B
마지막 기여는 DataComp-1B라는 새로운 multimodal dataset입니다.
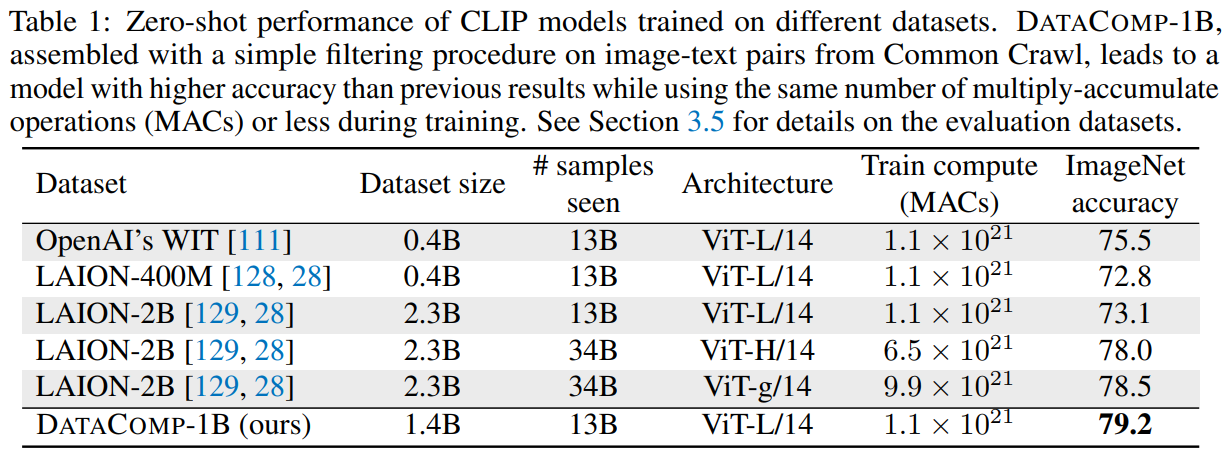
DataComp-1B는 두 가지 유망한 filtering baseline을 결합해서 만들었고, 이 데이터로 CLIP ViT-L/14를 학습했을 때 ImageNet zero-shot **79.2%**를 달성했습니다. 이는 OpenAI original CLIP ViT-L/14보다 3.7%p 높고, 같은 compute budget을 사용했다고 설명
논문 표 1에서도 DataCom p-1B가 LAION-400M, LAION-2B, OpenAI WIT보다 높은 ImageNet zero-shot 성능을 보입니다.
즉, DataComp는 멀티모달 데이터셋 설계를 체계적으로 연구할 수 있는 출발점이될 수 있다.