[2026-1] 김지원 - Learning Transferable Visual Models From Natural Language Supervision
논문: Learning Transferable Visual Models From Natural Language Supervision (OpenAI, 2021)
저자: Alec Radford, Jong Wook Kim, Chris Hallacy, et al.
링크: arXiv | GitHub
들어가며
기존의 이미지 분류 모델(ResNet, EfficientNet 등)은 미리 정의된 클래스 집합 안에서만 예측이 가능함. ImageNet으로 학습된 모델은 1,000개의 클래스만 알며, 새로운 클래스를 추가하려면 또 다시 대규모의 라벨링 데이터가 요구됨. 이러한 제약된 형태의 지도 학습은 모델의 일반화 능력과 활용성을 크게 제한함.
CLIP(Contrastive Language-Image Pre-training) 은 이 패러다임을 전환함. 인터넷에서 수집한 4억 개의 (이미지, 텍스트) 쌍으로 학습하여, 자연어 자체를 지도 신호(supervision)로 사용함. 그 결과:
- ImageNet의 128만 장 학습 예제를 전혀 사용하지 않고도 ResNet-50과 동일한 정확도를 달성함.
- OCR, 동작 인식, 지리적 위치 추정, 세분화된 품종 분류 등 30개 이상의 서로 다른 태스크에 자연스럽게 전이됨.
핵심 아이디어: NLP의 성공 방식을 비전에 적용
GPT, BERT 계열의 NLP 모델은 라벨 없이 raw text만으로 광범위한 태스크에서 높은 성능을 기록함. 저자들은 다음과 같은 질문을 던짐.
"비전에서도 동일한 접근이 가능한가?"
기존 컴퓨터 비전 연구는 크게 세 가지 접근으로 구분됨.
| 접근 방식 | 예시 | 한계 |
|---|---|---|
| Gold-label (crowd-labeled) | ImageNet | 라벨링 비용이 큼, 클래스 고정 |
| Weak supervision (해시태그) | Instagram hashtags | 정적 softmax, 제로샷 어려움 |
| Raw text로 직접 학습 (초기) | VirTex, ICMLM | 규모가 작아 성능 낮음 (ImageNet 11.5%) |
CLIP은 세 번째 접근을 대규모로 확장함. 4억 쌍의 데이터(WIT: WebImageText)를 구축하고, Transformer 아키텍처와 대조 학습(Contrastive Learning)을 결합함.
학습 방법: Contrastive Pre-training

첫 번째 시도: 캡션 예측 방식의 실패
초기 저자들은 VirTex와 유사하게 이미지를 보고 캡션 단어를 직접 생성하는 방식을 시도함. 그러나 이 방식은 확장에 어려움을 겪음.
하나의 이미지에 달릴 수 있는 자연어 텍스트는 매우 다양함. 동일한 대상에 대해서도 설명문, 해시태그, 댓글 등 형태가 제각각임. 이 중 "정확히 어떤 문장이 달렸는지" 예측하는 것은 매우 비효율적인 학습 목표임. 실제로 Transformer 기반 언어 모델은 단순 Bag-of-Words 예측보다 ImageNet 제로샷 정확도 달성에 3배 느림.

해결책: Contrastive Objective
저자들은 목표를 단순화함. 캡션의 정확한 단어 예측 대신:
"배치 안의 N개 이미지와 N개 텍스트 중, 실제로 짝을 이루는 쌍은 어떤 것인가?"
만 맞히도록 학습함.
이것이 Contrastive Learning의 핵심 아이디어

수식 정리
배치 크기 $N$일 때:
- 이미지 인코더 $f_{img}$: 이미지 → $d$차원 벡터 $I_1, I_2, ..., I_N$
- 텍스트 인코더 $f_{txt}$: 텍스트 → $d$차원 벡터 $T_1, T_2, ..., T_N$
- 두 벡터를 동일한 multimodal embedding space로 선형 투영
- $N \times N$ 유사도 행렬을 구성:
- 대각선($N$개의 실제 쌍): 코사인 유사도 최대화
- 비대각선($N^2 - N$개의 가짜 쌍): 유사도 최소화
- 대칭 Cross-Entropy Loss로 최적화
# 핵심 의사코드 (논문 Figure 3)
I_f = image_encoder(I) # [N, d_i]
T_f = text_encoder(T) # [N, d_t]
I_e = l2_normalize(I_f @ W_i, axis=1) # 멀티모달 임베딩
T_e = l2_normalize(T_f @ W_t, axis=1)
logits = (I_e @ T_e.T) * np.exp(t) # 코사인 유사도 * 온도
labels = np.arange(N) # 정답은 대각선
loss_i = cross_entropy(logits, labels, axis=0)
loss_t = cross_entropy(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2이 objective는 Deep Metric Learning의 multi-class N-pair loss(Sohn, 2016)로 처음 제안되었고, InfoNCE(Oord et al., 2018)로 널리 알려짐. Bag-of-Words 예측 대비 4배, Transformer 언어 모델 대비 12배 제로샷 효율 향상이 관찰됨.
구현 세부사항
- 이미지 인코더와 텍스트 인코더는 처음부터 학습 (ImageNet 가중치 초기화 사용하지 않음)
- 표현 공간과 대조 임베딩 공간 사이에 비선형 투영 대신 선형 투영만 사용
- 학습 가능한 온도 파라미터 $\tau$는 log-parameterized multiplicative scalar로 직접 최적화
- 이미지 증강은 random square crop만 사용
- 배치 크기 32,768, mixed precision, gradient checkpointing 활용
- 최대 모델(RN50x64)은 V100 GPU 592개로 18일, ViT-L/14는 256개 GPU로 12일 학습
Zero-Shot Transfer 작동 원리

학습이 완료되면 CLIP은 학습 중 본 적 없는 새로운 데이터셋에 대해 분류가 가능함.
작동 과정
- 데이터셋의 모든 클래스 이름을 프롬프트로 변환 (예: "A photo of a dog.", "A photo of a cat.")
- 텍스트 인코더로 각 프롬프트의 임베딩 계산
- 분류할 이미지를 이미지 인코더로 임베딩 계산
- 코사인 유사도 기반으로 가장 가까운 텍스트 임베딩의 클래스를 예측
이 관점에서 보면, 이미지 인코더는 feature extractor이고, 텍스트 인코더는 자연어 입력으로부터 선형 분류기의 가중치를 생성하는 hyper-network(Ha et al., 2016)로 해석됨.
Prompt Engineering
클래스 이름만 단독으로 사용하는 것("dog")보다 문장 형태로 감싸는 것("A photo of a dog.")이 ImageNet 정확도를 1.3% 향상시킴. 이는 사전 학습 데이터의 텍스트가 대부분 완전한 문장 형태이기 때문으로 추정됨. 단어 하나만 주면 학습 분포와 테스트 분포 사이의 차이가 발생함.
데이터셋 특성에 따라 템플릿을 맞춤화하면 추가 성능 향상이 가능함.
| 데이터셋 | 프롬프트 |
|---|---|
| Oxford Pets | "A photo of a {label}, a type of pet." |
| Food101 | "A photo of {label}, a type of food." |
| FGVC Aircraft | "A photo of a {label}, a type of aircraft." |
| EuroSAT (위성) | "A satellite photo of {label}." |
| OCR 데이터셋 | "{label}" (따옴표 처리) |
또한 프롬프트 앙상블도 효과적임. 80개의 서로 다른 템플릿("a big photo of a {}", "a small photo of a {}" 등)으로 생성한 텍스트 임베딩을 평균 내면 ImageNet에서 추가 3.5% 향상됨.
앙상블은 확률 공간이 아닌 임베딩 공간에서 수행하므로, 평균화된 임베딩을 한 번 캐싱해 두면 이후 추론 비용은 단일 분류기와 동일함. Prompt Engineering과 앙상블을 결합하면 ImageNet 제로샷 정확도가 거의 5% 향상됨.
실험 결과
1. Zero-Shot CLIP vs Fully-Supervised ResNet-50
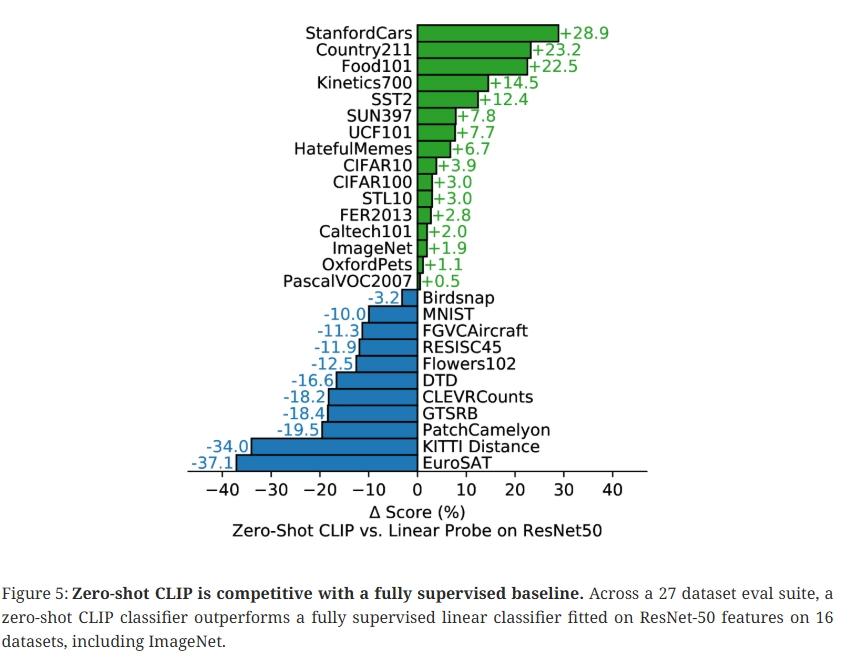
27개 데이터셋 중 16개에서 제로샷 CLIP이 완전 지도 학습된 ResNet-50 linear probe를 능가함. 데이터셋별 성능 편차를 분석하면 일정한 패턴이 관찰됨.
- CLIP 우세: Stanford Cars (+28.9%), Food101 (+22.5%), Kinetics700 (+14.5%)
- CLIP 열세: EuroSAT 위성 (-37.1%), KITTI Distance (-34.0%), PatchCamelyon 종양 (-19.5%), GTSRB 교통 표지판 (-18.4%)
일반적인 객체 인식 태스크에서는 CLIP이 우수한 반면, 전문적이고 추상적인 태스크(의료, 위성, 자율주행)에서는 성능이 낮음. 이는 사전 학습 데이터 분포(인터넷 이미지)의 특성을 반영한 결과로 해석됨.
비디오 동작 인식(Kinetics700, UCF101)에서 CLIP이 ResNet-50을 크게 상회하는 점도 주목할 만함. ImageNet의 명사 중심 라벨과 달리 자연어는 동사를 포함한 폭넓은 시각적 개념을 포괄하기 때문으로 추정됨.
2. Zero-Shot CLIP이 Few-Shot Linear Probe와 맞먹는 이유

Zero-shot CLIP이 같은 feature space의 4-shot linear probe와 유사한 성능을 보임. 이는 직관과 반대되는 결과임.
저자들의 해석은 다음과 같음. 일반적인 지도 학습은 훈련 예제로부터 개념을 간접적으로 추론해야 함. 그러나 하나의 이미지에는 여러 시각적 개념이 혼재되어 있어, 적은 수의 예제로는 어떤 개념이 목표인지 모호함. 반면 CLIP의 자연어 기반 분류기는 시각적 개념을 직접 명시할 수 있어, 이 모호성 문제를 회피함.
Zero-shot CLIP은 16-shot BiT-M ResNet-152x2와 거의 동일한 평균 성능을 기록함.
3. Scaling Law

CLIP도 GPT 계열과 유사하게 연산량에 따라 log-log linear로 제로샷 성능이 향상됨. 5개 ResNet 모델에 걸쳐 44배의 연산량 범위에서 매끈한 스케일링 곡선을 보여줌. 다만 개별 태스크 단위의 분산은 상대적으로 큼.
4. Representation Learning: Linear Probe 평가
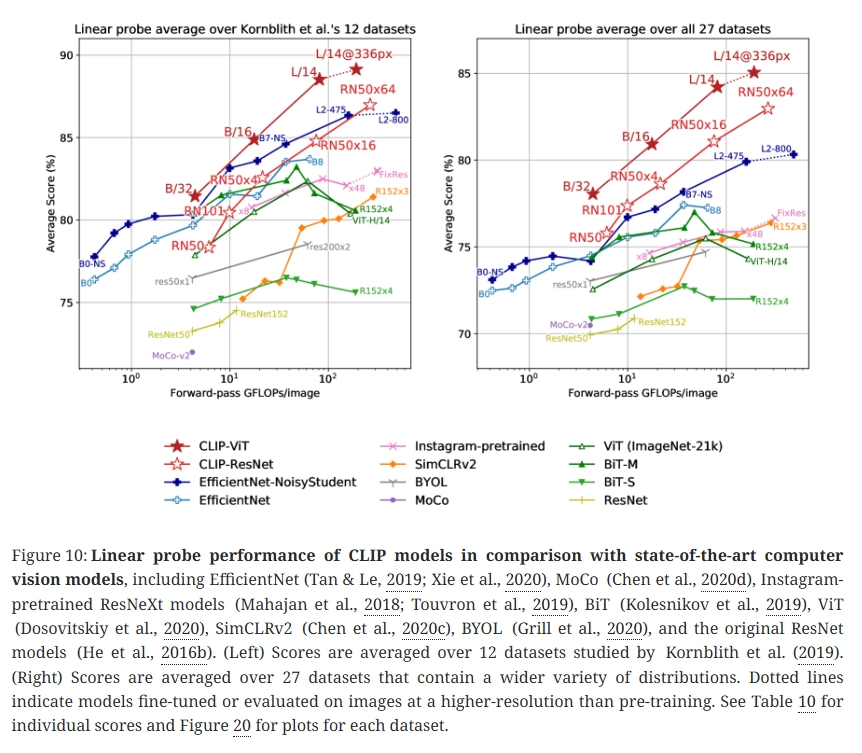
CLIP feature 위에 선형 분류기를 올려 평가한 결과:
- Kornblith et al. (2019)의 12개 데이터셋: 가장 큰 CLIP 모델(RN50x64)이 기존 SOTA였던 Noisy Student EfficientNet-L2를 소폭 상회함
- 27개로 확장한 평가셋: 평균 2.6~5% 향상, 모든 연산량 구간에서 최고 효율성
CLIP Vision Transformer는 CLIP ResNet보다 약 3배 더 계산 효율적이며, 이는 대규모 데이터셋에서 ViT가 CNN보다 효율적이라는 Dosovitskiy et al.(2020)의 관찰과 일치함.
Robustness: 분포 변화에 대한 강건성
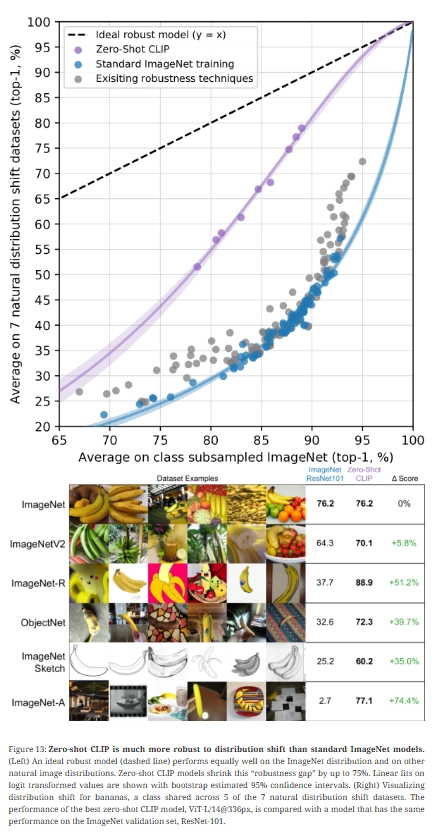
이 부분이 CLIP의 가장 중요한 기여 중 하나임.
배경: ImageNet 모델의 취약성
Taori et al. (2020)은 ImageNet 모델이 자연적 분포 변화(natural distribution shift)에 취약하다는 것을 체계적으로 보임. ResNet-101은 ImageNet 검증셋 대비 7개 분포 변화 데이터셋에서 5배 더 많은 오류를 기록함.
- ImageNetV2 (동일한 방식으로 재수집)
- ImageNet-R (렌더링, 스케치, 그림)
- ObjectNet (실생활 물건)
- ImageNet-A (자연스러운 adversarial 예제)
- ImageNet Sketch
- Youtube-BB, ImageNet-Vid
CLIP의 결과
Zero-shot CLIP은 이 robustness gap을 최대 75%까지 해소함.
| 데이터셋 | ResNet-101 | Zero-shot CLIP | 차이 |
|---|---|---|---|
| ImageNet | 76.2% | 76.2% | 0% |
| ImageNetV2 | 64.3% | 70.1% | +5.8% |
| ImageNet-R | 37.7% | 88.9% | +51.2% |
| ObjectNet | 32.6% | 72.3% | +39.7% |
| ImageNet Sketch | 25.2% | 60.2% | +35.0% |
| ImageNet-A | 2.7% | 77.1% | +74.4% |
Taori et al. (2020)의 관점에서 CLIP은 effective robustness를 크게 향상시킴. 즉, 단순히 상대적 성능만 높은 것이 아니라, 분포 내 정확도와 분포 외 정확도 사이의 기존 추세선 자체를 위로 밀어 올림.
Fine-tuning 이후의 변화
흥미로운 반례도 존재함. CLIP을 ImageNet으로 fine-tuning(linear probe with L2-regularized logistic regression)하면:
- ImageNet 정확도: +9.2% (85.4% 달성, 2018년 SOTA 수준)
- ImageNet-R: -4.7%
- ObjectNet: -3.8%
- ImageNet Sketch: -2.8%
- ImageNet-A: -1.9%
ImageNet 정확도 9.2% 향상은 SOTA 기준 약 3년의 개선에 해당함에도 불구하고, 분포 변화 평가에서는 성능이 오히려 저하됨. ImageNet 분포에 대한 적응 과정에서 분포에 고유한(spurious) 상관관계가 학습되어 일반화 성능을 해치는 것으로 해석됨.
이 결과는 두 가지 시사점을 줌.
- ImageNet 단일 지표에 집착하는 기존 평가 방식은 실제 모델의 "일반적인" 성능을 과대평가할 수 있음
- Task-agnostic pre-training + 광범위한 zero-shot 평가가 더 강건한 시스템 개발을 촉진함
인간과의 성능 비교

Oxford IIT Pets 데이터셋(37개 개/고양이 품종)으로 5명의 사람과 CLIP을 비교한 실험 결과:
| 조건 | 정확도 |
|---|---|
| Zero-shot 인간 | 53.7% |
| Zero-shot CLIP | 93.5% |
| One-shot 인간 | 75.7% |
| Two-shot 인간 | 75.7% |
정확도 자체는 CLIP이 압도적으로 우세하지만, 학습 동역학에는 흥미로운 차이가 있음.
인간은 예시 1장만 보면 54% → 76%로 정확도가 급상승하지만, 예시 2장을 줘도 추가 향상이 없음. 저자들의 분석에 따르면 이 성능 향상은 거의 전적으로 인간이 처음에 불확실하다고 판단한 이미지에서 발생함. 즉, 인간은 자신이 무엇을 모르는지를 인지(meta-cognition)하고, 해당 영역에서 선택적으로 prior를 업데이트함.
CLIP을 포함한 현재의 few-shot 학습 알고리즘은 이러한 능력이 부족함. Few-shot 학습에 prior knowledge를 효과적으로 통합하는 방법이 향후 중요한 연구 방향임을 시사함.
또한 CLIP이 어려워하는 품종은 인간도 어려워함. 오류의 상관성은 데이터셋 노이즈 또는 out-of-distribution 이미지에서 공통적으로 발생하는 어려움에서 기인하는 것으로 보임.