[2025-2] 정재훈 - Going deeper with convolutions
https://arxiv.org/pdf/1409.4842
0. Abstrct
이 논문은 ILSVRC 2014에서 이미지 분류(Classification)와 객체 탐지(Detaction)에서 SOTA를 달성한 architecture Inception 을 제안합니다.
Computational budget을 유지하며 architecture의 width 와 depth를 증가시켰습니다.
Hebbian principle과 multi-scale processing의 직관을 참고하여 architecture을 설계하였습니다.
1. Introduction
2012~2014동안 이미지 인식 성능이 많이 성장하였으나 이는 하드웨어의 발전이나 데이터 양의 증가보다 새로운 아이디어, 알고리즘, 네트워크 구조의 영향이 더 큽니다.
본 연구에서는 computational budget을 15억회로 유지하며 성능을 향상시키고자 하였고 이는 학문적 호기심에서 끝나는 것이 아닌 실제 세상에서 합리적인 비용으로서 이용될 것을 고려하며 설계하였습니다.
연구팀는 Network in network와 Provable bounds for learning some deep representations의 논문에서 영감을 받아 Inception 모델을 제작하였습니다.
2. Related Work
Y.LeCun의 LeNet-5와 같이 convolution-normalization-pooling 구조의 CNN을 따르고 있습니다.
Network in Network에서 영감을 받아 1*1 convolutional layer을 사용하였습니다. 이는 모든 convolution layer에서 나온 결과값에 ReLU를 적용하고 dimemsion 감소시켜줍니다.
또한 목표 물체가 있을 법한 영역(potential object proposal)을 찾고 그 영역 내에서 CNN을 통해 분류하는 R-CNN의 방식을 따라 설계하였습니다. 하지만 multi-box를 이용하여 두 단계에서 모두 향상을 이루어냈습니다.
3. Motivation and High Level Conseiderations
딥러닝 모델의 성능을 가장 직접적으로 높이는 방법 네트워크의 깊이와 넓이를 키우는 것입니다.
하지만 네트워크의 깊이와 넓이를 키우는 것은 overfitting과 급격한 연산량 증가라는 2가지 단점을 가지고 있습니다.
이를 근본적으로 해결하는 방법은 layer 사이에서의 연결을 sparsely(희소)하게 하는 것입니다.
Arora 연구팀에 따르면 확률 분포를 크고 sparse(희소)하게 나타낼 수 있다면 최적의 구조를 만들 수 있습니다.
하지만 data 구조가 균일하지 않고 sparse(희소)한 형태를 가지고 있다면, overhead of lookups와 cache misses의 문제들이 발생하여 연산 속도가 훨씬 느려지는 문제가 발생합니다.
이에 연구팀은 dense한 모듈을 통해 sparse한 구조를 만들고자 합니다. 즉, 성향이 비슷한 dense한 모듈들끼리 sparse하게 연결하여 Topology를 만들고자 합니다.
4. Architectural Details
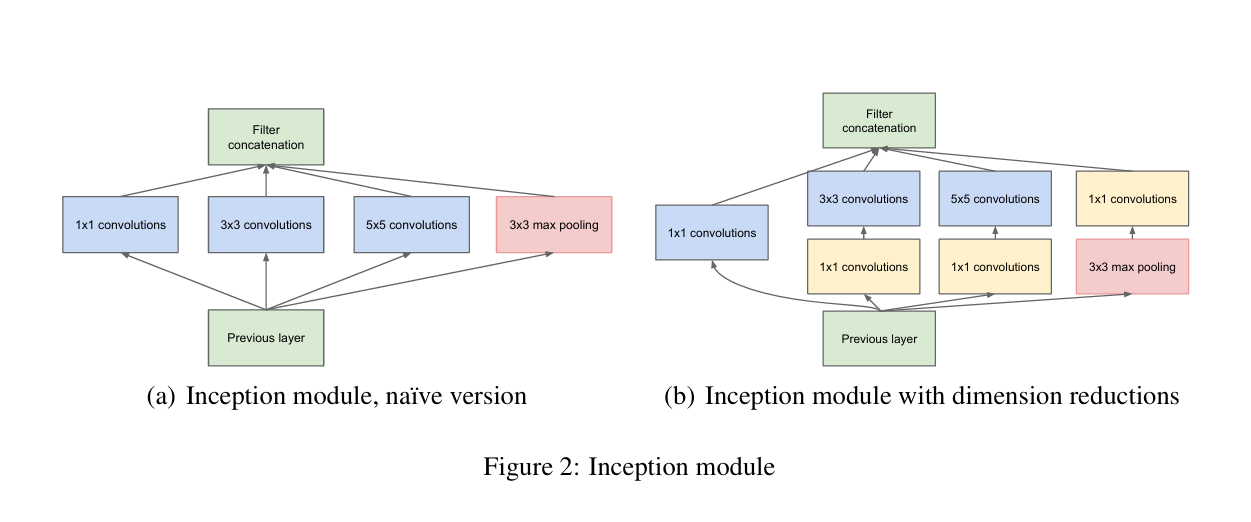
왼쪽 2(a)는 Inception 모듈의 최초 구상을 오른쪽 2(b)는 실제 GoogLeNet에 적용된 inception 모듈을 나타낸 것입니다.
2(a)는 1x1 convoulution, 3x3 convolution,5x5 convolution, 3x3 max-pooling 필터가 병렬적으로 놓여져 있으며 이전 층에서 나온 모든 input을 모든 필터에 통과시키는 것입니다. 또한 이 필터들을 통과한 결과물들의 크기 (가로 x 세로)를 맞추어 채널 방향으로 합친 결과물을 도출합니다.
하지만 2(a)와 같은 모듈을 사용했을 경우 채널이 과하게 증가하여 몇 단계도 못 가서(within a few stages) 연산량이 폭발하기 때문에 2(b)와 같이 convolution 필터 전 후로 1x1 convolution 필터를 적용하여 채널수를 줄입니다.
이를 통해 연산량 감소와 비선형성을 얻을 수 있습니다.
5. GoogLeNet


다음은 GoogLeNet의 구조와 연산 횟수를 나타낸 것입니다.
파라미터가 있는 층의 개수는 22개, pooling을 포함하면 27층입니다.
Inception 층을 제외한 특이한 층들 중에는 global average pooling, auxiliary classifiers, dropout이 있습니다.
6. Training Methodology
GoogLeNet의 학습의 특징은 다음과 같습니다.
-CPU 클러스터 병렬적 사용
- Asynchronous SGD with momentum 0.9
-8에폭마다 학습률 8%감소
-데이터 크기 및 비율, 색상 변형을 통한 증강(Argumnetation)
7. ILSVRC 2014 Classification Challenge Setup and Results
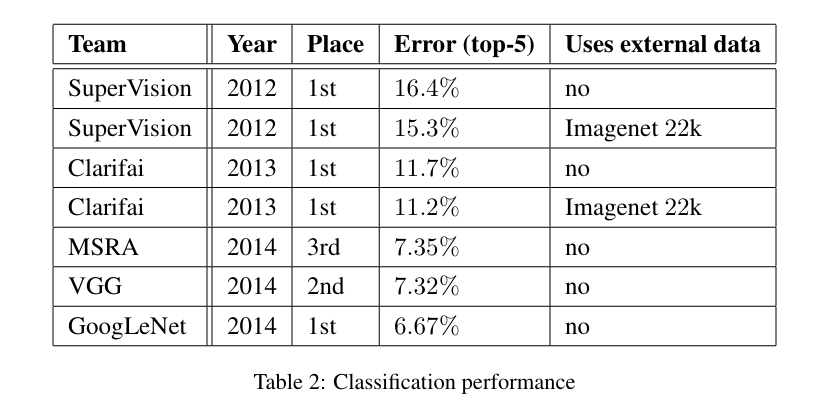
ILSVRC 2014 Classification Challenge에서 다음과 같은 2가지의 전략을 사용하였습니다.
-7개의 모델에 데이터 순서를 바꾸어 학습 후 예측값의 평균을 냄
-이미지를 144개로 나누어 검사
이를 통해 GoogLeNet은 오차율(top-5)에서 6.67%로 가장 낮은 오차율을 보였습니다.
8. ILSVRC 2014 Detection Challenge Setup and Results

ILSVRC 2014 Detection Challenge에서 R-CNN의 구조와 유사하지만 기존 R-CNN과는 다르게 분류기를 inception모듈로 대체하고 다음과 같은 전략을 사용하였습니다.
-6개의 모델에 데이터 순서를 바꾸어 학습 후 예측값의 평균을 냄
이를 통해 GoogLeNet은 정확도(mAP)에서 43.9%로 가장 낮은 오차율을 보였습니다.
9. Conclusions
우리는 다음과 같은 결론을 얻을 수 있었습니다.
1. 희소한 구조(Sparse Structure)을 밀집된(dense) 모듈로 나타낼 수 있음.
2. 더 적은 연산량으로 더 높은 성능을 구현할 수 있음.
3. Inception 모듈 자체에 대한 성능 및 잠재력을 확인함.