Multi-Modal
[2025-2] 박제우 - ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING FOR ZERO-SHOT ANOMALY DETECTION
jw2463
2025. 9. 27. 11:16
https://arxiv.org/abs/2310.18961
AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection
Zero-shot anomaly detection (ZSAD) requires detection models trained using auxiliary data to detect anomalies without any training sample in a target dataset. It is a crucial task when training data is not accessible due to various concerns, eg, data priva
arxiv.org
0. Abstract
- 제로샷 이상탐지(ZSAD)는 훈련 샘플이 없을 때 Auxiliary data를 사용해 훈련된 탐지 모델이 이상을 감지할 수 있어야 한다.
- 지금까지의 VLM은 이미지의 이상 여부보다는 class semantics를 중점적으로 학습한다.
- CLIP을 다양한 도메인에 걸친 ZSAD에 적응시키기 위한 접근, 이미지 객체와는 무관하게 이미지 속의 일반적인 정상과 이상을 포착할 수 있는 텍스트 프롬프트를 학습.
1. Introduction
- 기존의 이상 탐지 방식은 대상 도메인에서의 훈련 샘플이 제공된다는 가정을 한다. 그러나 이는 매번 적용되지는 않을 수 있다. → 제로샷 이상탐지
- 제로샷 이상탐지를 위해 도메인 일반화가 가능해야함
- 기존 VLM 모델 역시 이상탐지를 위해 사용되지만 CLIP은 이미지의 클래스에 맞게 학습되어 있고, 기존의 프롬프트 엔지니어링 방식으로는 대부분 수작업으로 이루어짐.
- 또한 다른 도메인에서의 일반화 성능도 아직 알 수 없음
Contribution
- ZSAD를 위한 object agnostic 텍스트 프롬프트를 학습
- Anomaly CLIP 제안 : object agnostic prompt template & 글로컬 손실 함수 사용
- 높은 도메인 일반화 성능 확인
2. Preliminary
- 기본적으로 CLIP은 텍스트 인코더 T와 이미지 인코더 F로 구성된다.
- 특정 클래스 이름 c를 포함하는 텍스트 프롬프트 템플릿 G를 T에 통과시켜 텍스트 임베딩 생성
- “A photo of a [cls]”
- 이미지는 비전 인코더를 통해 인코딩, 이를 통해 글로벌 / 로컬 임베딩을 얻음(클래스 토큰 / 패치 토큰)
- CLIP은 텍스트 임베딩과 이미지 임베딩간의 코사인 유사도를 측정함으로써 제로샷 분류 수행.

- 본 연구에서는 객체 이름보다도 정상/이상 여부를 중심으로 확인할 예정
- 따라서 기존 CLIP에서는 각 클래스에 속할 확률을 표시했지면 여기서는 이게 Anomaly Score가 된다.
3. AnomalyCLIP : Object Agnostic Prompt Learning
3.1 Approach Overview

3.2 Object-Agnostic Text Prompt Design
- 프롬프트에서 객체 이름을 제거하고 “Object”라는 일반 용어로 대체
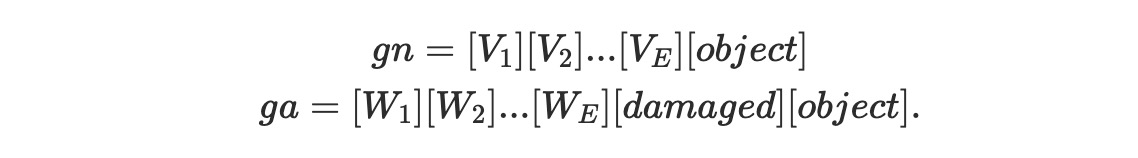
3.3 Learning Generic Abnormality and Normality Prompts
Glocal Context Optimization
- Glocal Optimization : 전체적인 이상여부 뿐만 아니라 국소적 이상 부위까지 함께 학습.
- Glocal Loss :


Text Space Refinement
- CLIP의 텍스트 인코더를 Anomaly Detection에 맞게 조금씩 변형한다. → 앞 쪽 토큰 일부를 학습 가능하게 바뀐다.
- 원래 CLIP은 거대한 범용 데이터셋에서 학습된 모델이기 때문에 이상탐지에 어울리게 변형한다는 뜻이다.
Refinement of the local visual space
- CLIP의 이미지 인코더는 원래 Global Embedding에 더 특화되어 있다.
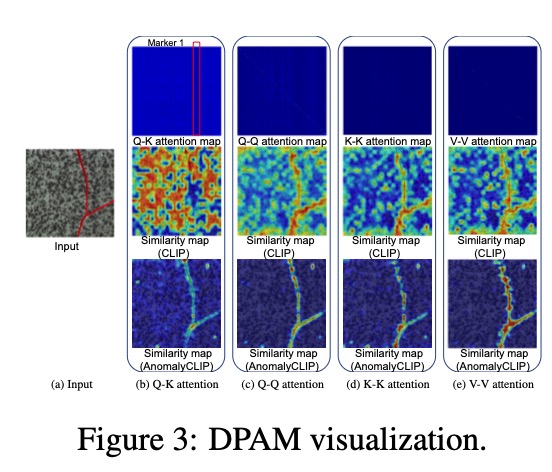
- 따라서 이들은 국지적 어텐션을 방해한다.
- 본 연구에서 제안한 위 DPAM 방식은 어텐션을 Q, K, V 레벨로 분석해서 어느 부분이 진짜 Anomaly인지 시각적 분석.
- AnomalyCLIP은 정상/비정상 구분에 필요한 미세한 특징을 잘 잡기 위해 → 기존의 Q-K 대신 → Q-Q, K-K, V-V 같은 자기중심(Self-to-self) attention을 사용한다. 논문에서는 실험 결과 V-V attention이 가장 성능이 좋았다고 하여 최종적으로 채택된다.
4. Experiments
4.1 Experiment Setup
Datasets and Evalutation Metrics
- 17개의 의료/산업 이상치 탐지
4.2 Main Results

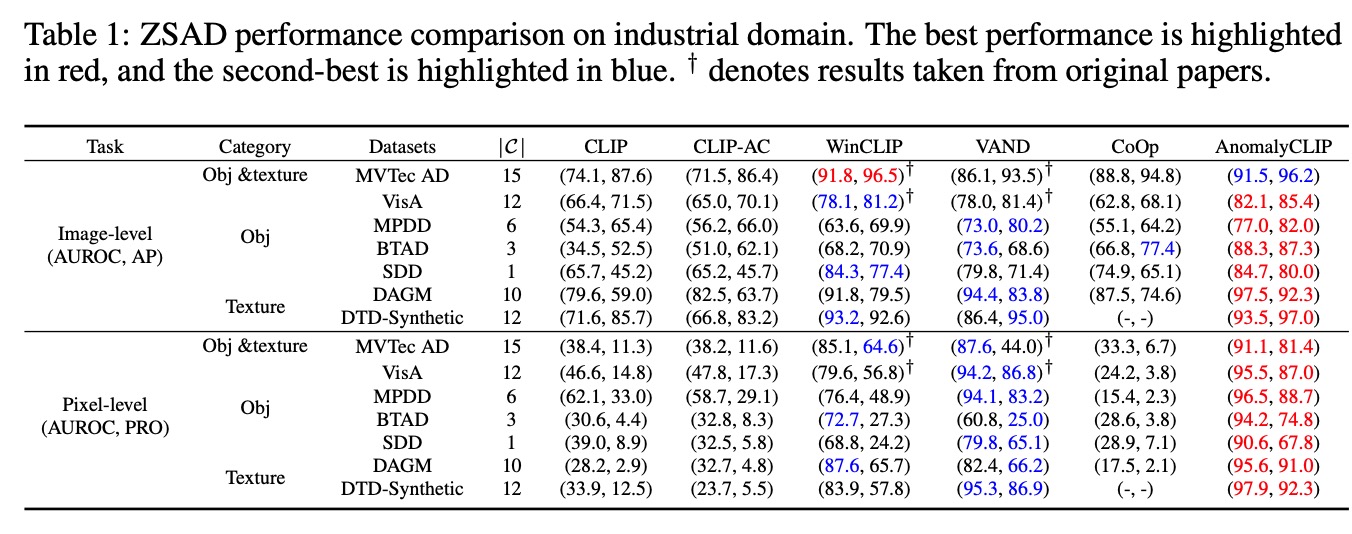
- 그림 4를 보면 AnomalyCLIP이 훨씬 더 이상치를 잘 탐지하는 것을 볼 수 있음
- 일반화 성능을 더 판단하기 위해 산업용 결합 데이터셋에서 학습한 모델을 이미지 데이터에 적용한다.