Miscellaneous
[2025-2] 이루가 - Rumor Detection on Social Media with Bi-Directional Graph ConvolutionalNetworks
wnfladl
2025. 7. 27. 13:38
논문 링크: https://arxiv.org/abs/2001.06362
Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks
Social media has been developing rapidly in public due to its nature of spreading new information, which leads to rumors being circulated. Meanwhile, detecting rumors from such massive information in social media is becoming an arduous challenge. Therefore
arxiv.org
ABSTRACT
- 소셜 미디어에서 루머가 빠르게 전파되고 광범위하게 확산
- 기존 딥러닝 모델이 깊은 전파만 고려하고 넓은 확산 구조를 간과함
- 루머 탐지를 위해 전파와 확산을 동시에 반영한 양방향 그래프 구조의 필요성
- 전파 경로를 학습하기 위한 상향(top-down) 방향 GCN의 적용
- 확산 구조를 포착하기 위한 하향(bottom-up) 방향 GCN의 적용
- 각 GCN 층마다 루머의 출처 정보를 포함시킨 근원 정보 강화 전략
- 전파 패턴과 확산 구조를 모두 반영한 Bi-GCN 모델의 설계
- 여러 벤치마크에서 기존 최신 모델보다 우수한 성능을 보인 실험 결과
- 루머 탐지 정확도 향상과 실생활 소셜미디어 응용 가능성 제시
INTRODUCTION
- 소셜미디어가 정보 공유와 의견 표현의 주요 수단이 된 현상
- 사용자 수와 참여도가 높아지면서 루머 발생이 급증
- 루머가 빠르게 확산되며 사회적 혼란과 경제적 피해를 초래
- 루머로 인한 공포와 위협에 대응하기 위한 조기 탐지 기술의 필요성
전통적인 방법
- 사용자 정보, 텍스트 내용, 전파 패턴 등을 활용한 handcrafted feature 기반 분류 모델의 사용
- Decision Tree, Random Forest, SVM 등 전통 모델에 대한 의존
- 수작업 특징 추출의 시간 소모성과 효율성 부족
- 루머 전파 구조로부터 얻을 수 있는 고수준 표현 부족
기존 딥러닝 모델의 한계
- LSTM, GRU, RvNN 등 시퀀스 기반 모델의 활용
- 전파 경로 중심의 시간적 패턴 학습에 치중된 접근
- 루머의 넓은 확산 구조(dispersion)를 반영하지 못하는 한계
- CNN을 활용한 국소 이웃 간 관계 학습의 시도
- CNN의 한계로 인해 그래프 전체 구조에 대한 이해 부족
GCN의 등장과 적용 고민
- 다양한 분야(SNS, 물리 시스템, 약물 발견 등)에서의 GCN 성공 사례
- 루머 탐지에 GCN을 바로 적용할 수 있을지에 대한 의문
- 기존 GCN(UD-GCN)은 노드 간 관계만 고려하고 전파 방향성은 무시
- 루머 탐지에서 중요한 전파 방향성과 구조적 확산을 반영하지 못하는 문제
논문의 제안: Bi-GCN
- 루머의 top-down propagation과 bottom-up dispersion을 동시에 학습하는 모델 설계
- 각각의 방향성에 대해 TD-GCN, BU-GCN을 구성
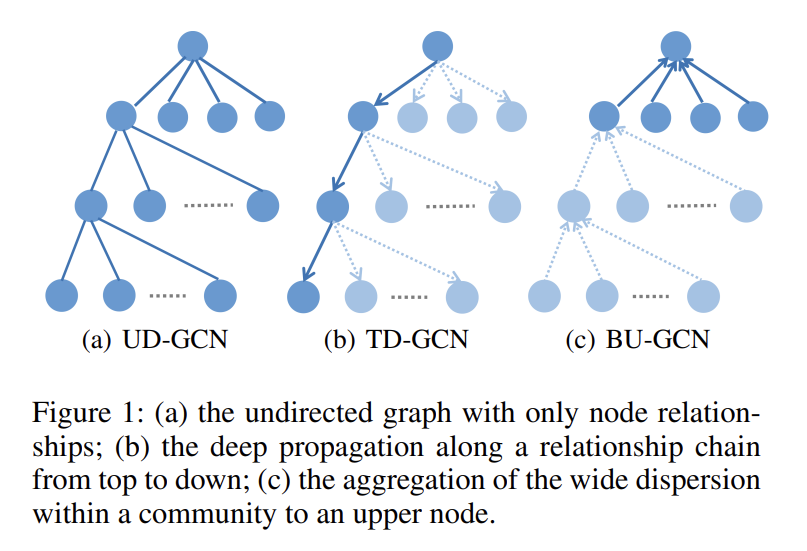
- 부모 → 자식, 자식 → 부모 방향으로 정보를 전파하며 양방향 구조 학습 수행
- 각 레이어마다 루머의 출처(root post) 정보를 추가로 결합해 근원 정보 강화
- DropEdge 기법을 적용해 학습 시 overfitting 방지
RELATED WORK
초기 연구: 전통 기반 방법들
- 텍스트 내용, 사용자 프로필, 전파 구조 등에서 특징을 추출한 후 분류기를 학습하는 방식의 접근
- 시계열 데이터를 활용해 사회적 맥락 특징의 변화를 모델링한 방식 (Ma et al., 2015)
- 그래프 커널 기반 하이브리드 SVM 분류기의 제안 (Wu et al., 2015)
- 전파 트리 구조 간 유사도 평가를 통한 트리 커널 모델 (Ma et al., 2017)
- 대부분의 모델이 핸드크래프트된 특징에 의존하고 효율이 낮았던 한계
딥러닝 기반 연구
- RNN을 활용한 시계열 기반 루머 표현 학습 (Ma et al., 2016)
- RNN에 Attention Mechanism을 결합하여 중요한 텍스트 특징에 집중한 모델 (Chen et al., 2018)
- CNN 기반 시퀀스 내 핵심 특징 추출 및 상호작용 학습 방법 (Yu et al., 2017)
- RNN과 CNN을 결합하여 사용자 시계열 특징을 함께 학습한 방식 (Liu et al., 2018)
- Adversarial Learning을 통해 분류기 성능을 향상시킨 방법 (Ma et al., 2019)
- 트리 구조 RvNN을 활용한 전파 구조 및 텍스트 통합 표현 학습 (Ma et al., 2018)
- 위 모델들의 공통된 한계는 전파 구조 학습의 비효율성과 루머 확산 구조의 미반영
GCN의 가능성과 본 논문의 차별성
- GCN은 그래프/트리 기반 데이터로부터 전역 구조적 특징을 효과적으로 학습할 수 있는 모델
- CNN이 시각 정보에서 보여준 성공처럼, GCN도 다양한 그래프 기반 문제에서 SOTA 성능을 입증
- 본 논문은 기존 GCN의 전파력과 구조 학습 능력에 기반하여 루머 탐지에 처음 GCN을 도입한 시도
Preliminaries
Notation
- 루머 탐지 데이터셋은 여러 개의 이벤트 단위 데이터(C = {c₁, c₂, ..., cₘ})로 구성됨
- 각 이벤트 cᵢ는 다음 요소를 포함
- rᵢ: 해당 이벤트의 출처가 되는 소스 포스트 (root post)
- wᵢ₁, wᵢ₂, ..., wᵢₙ: 소스 포스트에 대한 댓글/리트윗 등 응답 포스트들
- Gᵢ: 해당 이벤트의 전파 구조를 나타내는 그래프
<그래프 구조 정의>
- 노드 집합 Vᵢ: 하나의 이벤트 내 모든 포스트들 (rᵢ 포함)
- 엣지 집합 Eᵢ: 응답 관계를 기반으로 구성된 방향성 있는 엣지들
- 예: wᵢ₁이 rᵢ에 응답한 경우 → 엣지: rᵢ → wᵢ₁
- 예: wᵢ₂가 wᵢ₁에 응답한 경우 → 엣지: wᵢ₁ → wᵢ₂
- 인접 행렬 Aᵢ: 포스트 간 연결 여부를 0과 1로 표시한 행렬
- 엣지가 존재할 경우 1, 없을 경우 0
<포스트 특징 표현>
- 각 이벤트 cᵢ는 포스트별로 벡터화된 특징 행렬 Xᵢ를 가짐
- 각 행은 하나의 포스트(소스 또는 응답)의 텍스트, 사용자 정보 등을 벡터화한 값
<라벨 정의>
- 각 이벤트에는 정답 라벨 yᵢ가 지정됨
- 기본: {F, T} = False Rumor / True Rumor
- 세분화 가능: {N, F, T, U} = Non-rumor / False / True / Unverified
<최종 목표>
- 데이터셋 C가 주어졌을 때,
→ 각 이벤트의 텍스트, 사용자 정보, 전파 구조를 바탕으로
→ 라벨 yᵢ를 예측하는 분류기 f(C) → Y를 학습하는 것
Graph Convolutional Networks
- 최근 딥러닝 연구에서는 이미지(CNN)뿐만 아니라, 소셜 네트워크, 분자 구조 같은 그래프 기반 데이터를 처리할 수 있는 모델이 주목받고 있음
- GCN은 이러한 비정형 구조(non-Euclidean domain)에서도 학습이 가능하도록 만든 대표적인 모델
- 기본 아이디어:
→ 노드가 이웃 노드들로부터 정보를 집계(aggregate)하고 갱신(update)
→ 즉, Message Passing 방식의 Convolution
<GCN의 기본 연산>

<정규화된 GCN 수식 (대표적인 구현)>

<핵심 특징 요약>
- 각 노드는 자신과 이웃 노드들의 임베딩 정보를 종합해 새로운 표현을 얻음
- 인접 노드의 정보만 사용하기 때문에 지역적 정보에 집중
- 여러 GCN 레이어를 쌓으면 더 멀리 있는 이웃의 정보까지 전파 가능
- GCN은 다양한 분야(추천 시스템, 화학 분자 예측, 소셜 네트워크 분석 등)에서 효과적으로 사용되고 있음
DropEdge
- DropEdge는 GCN 계열 모델에서 overfitting(과적합)을 줄이기 위해 제안된 정규화 기법
- GCN은 고정된 그래프 구조에 의존하기 때문에, 학습 과정에서 모델이 그래프 구조에 과도하게 적응(overfit)할 수 있음
- DropEdge는 이를 완화하기 위해, 학습 시 매 epoch마다 일부 엣지를 무작위로 제거하여
다양한 형태의 그래프를 만들어 학습하도록 유도함
<수식>

- 학습 시 매번 조금씩 다른 그래프 구조를 사용함으로써
→ 모델 일반화 성능 향상
→ 특정 엣지에 과도하게 의존하는 문제 방지 - 실험적으로도 DropEdge는 GCN 계열 모델에서 성능 향상과 과적합 완화에 효과적임이 입증됨
Bi-GCN Rumor Detection Model
- Bi-GCN은 루머의 확산(Propagation)과 분산(Dispersion)을 모두 학습하는 GCN 기반 모델
- 이를 위해 두 가지 방향의 GCN을 구성:
- TD-GCN (Top-Down GCN): 전파 방향 학습
- BU-GCN (Bottom-Up GCN): 확산 방향 학습
- GCN 구조는 모두 2-layer 1stChebNet을 사용
- DropEdge 기법을 통해 overfitting을 방지

1 Construct Propagation and Dispersion Graphs(전파 그래프와 확산 그래프 구성)
- 이벤트 cic_i의 전파 트리 기반으로 그래프 G = (V, E) 생성
- 노드 V: 루머 관련 포스트들
- 엣지 E: 응답 관계 (ex. r → w₁, w₁ → w₂)
- 인접 행렬 A 및 특징 행렬 X 정의
- DropEdge를 적용하여 일부 엣지 제거 후 A0=A−AdropA_0 = A - A_{\text{drop}} 계산
- 두 가지 그래프 구성:

2 Calculate the High-level Node Representations(고차원 노드 표현 학습)

3 Root Feature Enhancement
- 루머 이벤트의 source post(출처 포스트)는 의미 있는 정보를 가장 많이 담고 있음
- 따라서 모든 노드가 루트 노드로부터의 정보를 좀 더 직접적으로 전달받을 수 있도록
→ 각 GCN 레이어에서 루트 노드의 특징을 각 노드에 결합(concatenate)하는 구조 추가 - TD-GCN 기준 수

- BU-GCN도 동일 방식으로 루트 정보 결합 수행
4 Representations of Propagation and Dispersion for Rumor Classification(최종 표현과 분류)
- 고차원 표현 집계(Pooling)

- 최종 예측

- 전체 모델은 Cross-Entropy Loss를 사용해 학습
- L2 정규화도 모든 파라미터에 적용하여 과적합 방지
Experiments
Settings and Datasets
사용한 데이터셋 3종
- Weibo (중국): False Rumor (F), True Rumor (T) → 이진 분류
- Twitter15 / Twitter16 (미국): Non-rumor (N), False (F), True (T), Unverified (U) → 4개 클래스 다중 분류
- 각 노드는 사용자, 엣지는 리트윗/댓글 관계, 특징은 TF-IDF 상위 5000 단어 기반 벡터
- Twitter 데이터는 Snopes.com 등 팩트체크 사이트의 검증 태그,
Weibo는 Sina 커뮤니티 관리센터의 공식 레이블 기반으로 라벨링됨
실험 설정 및 구현 환경
- 모든 모델은 5-Fold Cross Validation을 통해 검증
- Bi-GCN은 Pytorch로 구현, DropEdge 비율은 0.2, Dropout 비율은 0.5
- 200 에폭 동안 학습하며, Early Stopping을 통해 과적합 방지
- Optimizer는 Adam, hidden vector 차원은 64
- SVM-TK는 Weibo 데이터셋에선 복잡도 문제로 제외
비교 대상 모델
<모델별 특징>
| DTC | Decision Tree 기반, 수작업 특징으로 신뢰도 판단 |
| SVM-RBF | 전체 통계 기반 handcrafted features + RBF 커널 |
| SVM-TS | 시계열 기반 SVM 분류기 |
| SVM-TK | 루머 전파 구조 기반 Tree Kernel SVM |
| RvNN | 트리 구조 기반 GRU-RNN, 전파 구조 학습 |
| PPC RNN+CNN | 사용자 정보 기반 RNN + CNN 통합 모델 |
| Bi-GCN | 상향/하향 전파 구조 모두 반영한 GCN 기반 모델 |
- 전통적 머신러닝부터 최신 딥러닝 모델까지 다양한 방식과 Bi-GCN의 성능을 비교
- 각 모델은 서로 다른 시각(텍스트, 구조, 시계열, 사용자)을 활용하여 루머 탐지를 수행
Overall Performance
1. 딥러닝 vs 전통 ML 모델
- 딥러닝 기반 모델이 수작업 특징 기반 모델 대비 전반적인 성능 우위 달성
- 딥러닝 모델의 고차원 표현 학습 능력이 루머 탐지의 핵심 특징 포착에 기여
- → 루머 탐지에서의 deep representation learning의 필요성과 중요성 확인
2. Bi-GCN vs PPC RNN+CNN
- Bi-GCN은 모든 평가 지표에서 PPC RNN+CNN을 상회하는 성능을 보임
- 그 이유는 RNN과 CNN이 그래프 구조를 직접 처리할 수 없는 한계 때문
- PPC RNN+CNN은 루머 확산 구조(dispersion)의 특징을 반영하지 못하는 단점 존재
- 반면, Bi-GCN은 top-down + bottom-up 구조를 모두 활용해 구조 정보 학습에 강점
3. Bi-GCN vs RvNN
- Bi-GCN은 RvNN보다 훨씬 더 안정적이고 정확한 성능을 보여줌
- RvNN은 리프 노드(마지막 포스트)의 hidden state만 사용하므로,
→ 정보가 부족하거나 의미 없는 최신 포스트에 지나치게 의존하게 됨 - Bi-GCN은 **source post의 정보(root feature)**를 전체 노드에 반복적으로 주입
→ 더 중요한 루머의 출처 정보를 효과적으로 반영할 수 있는 구조 설계


Ablation Study
비교 모델 구성
| UD-GCN | UnDirected GCN, 방향성 없는 그래프 기반 GCN |
| TD-GCN | Top-Down GCN, 루머 전파 방향 구조만 학습 |
| BU-GCN | Bottom-Up GCN, 루머 확산 방향 구조만 학습 |
| (no root) | 각 GCN 구조에서 root feature enhancement 미적용 |
| (root) | 각 GCN 구조에서 source post feature를 결합한 구성 |
| Bi-GCN | TD-GCN + BU-GCN + root feature enhancement 모두 포함한 제안 모델 |
결론 1: Root Feature의 효과
- 모든 GCN 모델(UD, TD, BU)에서 root feature를 포함한 버전이 더 우수한 성능을 달성
- → source post의 정보가 루머 탐지에서 매우 중요한 역할을 한다는 사실을 입증
결론 2: 단방향 구조의 한계
- TD-GCN과 BU-GCN은 경우에 따라 UD-GCN보다 나은 성능을 보이지 않음
- 즉, 한 방향만 고려하는 구조는 정보 손실 가능성이 존재
결론 3: Bi-GCN의 일관된 우위
- Bi-GCN은 모든 경우에서 다른 구조보다 높은 성능을 기록
- → 전파 방향(TD)과 확산 구조(BU)를 동시에 반영하는 방식이 가장 효과적임을 입증
- 심지어 가장 낮은 성능 결과조차도 기존 baseline 모델들보다 현저히 우수한 결과

Early Rumor Detection
- 루머를 전파 초기 단계에서 탐지하는 것은 확산 억제를 위한 핵심 과제
- 단순히 정확도뿐 아니라, 얼마나 빠르게 탐지 가능한가도 중요한 성능 지표
<실험 설정>
- 여러 시간 구간(Detection Deadline)을 설정하여,
각 시간 이전에 생성된 포스트만 사용해 루머 탐지 성능 측정 - PPC RNN+CNN은 시퀀스 길이 처리 제한 때문에 본 실험에서 제외
- 비교 대상: DTC, SVM-RBF, SVM-TS, RvNN
<결과>
- Bi-GCN은 source post가 처음 등장한 직후부터 높은 정확도를 달성
- 각 시간 지점마다 모든 다른 모델을 능가하는 성능을 기록
- → 그래프 구조 기반 표현 학습이 초기 탐지에도 효과적임을 입증

Conclusions
- 그래프 구조 학습이 가능한 GCN 기반 루머 탐지 모델 Bi-GCN의 제안
- Bi-GCN은 전파 경로(Top-down)와 확산 구조(Bottom-up)를 동시에 학습할 수 있는 구조를 가짐
- 각 레이어에 source post의 특징을 결합하여 루머의 근원 정보를 효과적으로 반영
- UD-GCN, TD-GCN, BU-GCN 등 단일 구조 모델과의 성능 비교를 통해 Bi-GCN의 우수성 입증
- root feature enhancement의 유효성 또한 실험을 통해 검증
- 전파와 확산을 동시에 고려한 Bi-GCN의 설계의 타당성 확인
- Weibo, Twitter15, Twitter16 세 개의 실제 소셜미디어 데이터셋에서 모든 baseline을 큰 폭으로 능가
- Bi-GCN은 정확도뿐 아니라 초기 탐지 능력(early detection)에서도 우수한 성능 달성
- GCN 기반 표현 학습이 루머 탐지 문제 해결에 매우 효과적인 방식임을 실증