[2025-2] 황징아이 - One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing

FaceVid2Vid 논문 : 2021년 CVPR Oral Paper (https://arxiv.org/pdf/2011.15126)
Introduction
코로나 때 줌과 같은 화상회의 플랫폼을 자주 사용하게 되었다. 하지만 인터넷 인프라가 부족하거나 Bandwidth가 부족한 환경에서는 영상이 뭉개지거나 지연되는 문제가 자주 발생했다. 이런 문제를 해결하기 위해, 본 논문은 단 한 장의 얼굴 이미지만으로 실제처럼 말하는 영상을 생성하는 방법을 제안한다.
기존의 얼굴 합성 (synthesizing) 방식은 크게 두 가지로 나눌 수 있다:
- 3D 기반 모델 : 얼굴의 입체 구조를 잘 반영하지만 학습 비용이 높고 복잡하다
- 2D 기반 모델 : 학습 효율은 좋지만 입체적인 정보를 보존하지 못해 대부분 정면 얼굴에만 국한되다
- → 고개를 돌리거나 다른 시점 (예 : 측면 모습) 을 보여주는것 이 불가능
이러한 한계점을 극복하기 위해, 3D Keypoint기반 표현을 사용해서 고개 회전과 시점 전환이 자연스러운 free-view talking head합성 방법을 제안하게된다.
3가지의 talking-head 합성 과제를 통해 모델 성능을 검증했다.
- Video Reconstruction : 원본 영상의 움직임을 정확히 복원할 수 있는지 평가
- Motion Transfer : 한 사람의 움직임을 다른 사람의 얼굴에 자연스럽게 적용하는지 확인
- Face Redirection : 시선, 고개 방향 등을 바꾸는 작업이 가능한지 테스트
[Fig.1]

Main Idea
아래 그림처럼 source image에서 얼굴 detail에 해당하는 생김새 정보를 추출하고, driving video에서 머리 포즈와 표정 정보를 추출해 talking-head를 합성한다. driving video의 머리 포즈 대신 임의의 머리 포즈 정보를 입력하여 원하는 포즈의 talking-head를 만들 수도 있다.

Method
- 입력 : 한장의 source image $s$와 driving video $\{d_1, d_2, \ldots, d_N\}$
- 출력 : source image의 얼굴에 driving video의 motion을 입히는 합성 talking-head 영상 $\{y_1, y_2, \ldots, y_N\}$을 생성하는 것을 목표로 한다

크게 3단계로 구성이 되어 있다.
- Source image feature extraction
- Driving video feature extraction
- Video generation
1. Source image feature extraction

- 3D Appearance Feature Extractor $F$ :
- 얼굴 생김새 정보 $f_s \in \mathbb{R}^{3}$

- Canonical Keypoint Detector $L$ :
- (K = 20개의) 사람 고유의 3D 얼굴 기준점 $x_{c,k} \in \mathbb{R}^{3}$
- Unsupervised하게 학습

- Head Pose Estimator $H$
- Headspace를 예측하는 회전행렬 $\mathbf{R}_s \in \mathbb{R}^{3\times 3}$ 와 평행이동백터 $\mathbf{t}_s \in \mathbb{R}^{3}$
- Rotation matrix : canonical view에서부터 머리가 얼마나 회전했는지를 나타내는 행렬
- Translation Vector : canonical view에서 부터 머리가 얼마나 이동했는지를 나타내는 백터
- Expression Deformation Estimator $\Delta$
- 표정 미세 변화 $\delta_{s,k} \in \mathbb{R}^{3}$

- Source Image Keypoint x_{s,k}를 계산 (Image specific and contain personal signature, pose, and expression information)

[Figure 4]
→ Source image feature extraction을 통해 사람의 얼굴 특징을 잘 분리해서 학습하고 있다는 것을 보여주고 있다.

*기존 FOMM 논문과 달리, 본 논문에서 는 Jacobian을 따로 예측할 필요가 없다는 장점이 있다.
- Jacobian는 키포인트 주변의 작은 패치가 다른 프레임에서 어떤 변환(회전·이동·스케일·전단)으로 바뀌는지를 나타내는 2 × 2 혹은 3 × 3 행렬이다.
- FOMM 방식 : 매 키포인트마다 Jacobian을 학습하면 모델이 무거워지고, 통신 데이터도 많이 늘어났다
- 본 논문의 접근 : 머리뼈를 강체(rigid) 라고 가정해서 지역 패치 변환은 Jacobian을 새로 예측하지 않아도, 머리 회전 행렬 $R_s$ 만으로 충분히 계산하고 ( $J_s \approx R_s$ )표정처럼 미세하게 움직이는 부분은 별도의 $\delta_{k}$로만 보정
-> 계산효율을 높일 수 있다.
2. Driving video feature extraction
Driving Video Feature Extraction을 통해 Motion정보를 추출.
Driving video를 frame단위로 나누고 각 프레임마다 (b) 과정을 진행 :

- Head Pose Estimator $H$ : Rotation Matrix $R_d$ & Translation Vector $t_d$를 추출
- Expression Deformation Estimator : Expression Deformation $\delta_{d,k}$ 를 추출
- Source image의 얼굴에 driving image의 모션을 입히는 것이기 때문에 canonical keypoint는 source image에서 구한 값을 가져와서 driving keypoints를 생성하게 된다.

3. Video generation

1. Warping Flow Map 계산
- 3D Source Keypoints 20개와 3D Driving Keypoints 20개를 쌍으로 대응시킨다.
- 각 Keypoints 쌍에대해 Source Keypoints에서 Driving Keypoints으로의 움직임을 표현하는 3D Warping Flowmap $w_k$를 계산. → First Order Approximation을 사용하여 구할 수 있다. (자세한 수식은 First Order Motion Model for Image Animation (Siarohin et al.) 논문 참고)

2. Source Feature Warping
- Source image feature $f_s$를 각 flow map $w_k$에 적용하면 warping된 3D feature $w_k(f_s)$를 얻게된다.
→ 총 20개의 warping된 3D feature $w_k(f_s)$를 얻게 되고, concatenate하여 Motion Field Estimator $M$에 입력값으로 넣어준다.
3. Motion Field Estimator (U-Net구조)
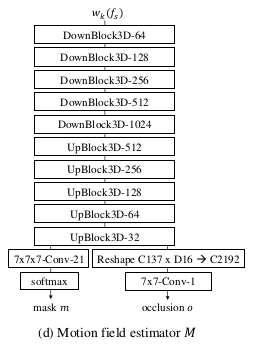
- Motion Field Estimator는 Flow Composition Mask와 Occlusion Mask를 출력한다.
- Flow Composition Mask : 20개 flow map의 가중합 비율을 결정하는 softmax
- Occlusion Mask : Source 이미지를 warping했을 때 가려져서 보이지 않는 영역을 표시 (예를 들어 고개 돌려서 source에 없던 귀를 generator가 새로 생성해야 할 부분을 알려주는 2D 마스크)
4. Final Warping Feature 생성
- Motion Field Estimaor에서 나온 flow composition mask와 20개의 flow map을 선형 결합하면 최종 warping flow map를 얻을 수 있다.
- Source appearance feature도 입력값으로 넣어서 최종 warping feature $w(f_s)$가 생성이되고 Generator의 입력값으로 전달.
5. Generator로 영상 복원
- Warping Feature $w(f_s)$를 3D → 2D로 투영
- Occlusion Mask를 곱해서 가려진 영역을 생성
- 2D Residual Block과 Up-Sampling을 통해 최종 이미지 y를 복원

Loss
학습에 사용된 Loss :

- Perceptual Loss $L_p(d, y)$ :
- Pre-trained VGG 모델 통과한 output image와 ground truth의 feature를 다양한 이미지 화질에서 3번 L1 loss를 사용하여 비교합니다. (논문 First order motion model for image animation를 참고)
- 기존 image를 down-sampling 해서 multi-scale loss를 계산하고, single-scale perceptual loss와 합산하여 최종 $L_p$를 얻는다
- GAN Loss $L_G(d, y)$ : “High-resolution image synthesis and semantic manipulation with conditional GANs” 논문에 소개된 hinge loss와 feature matching loss를 사용.
- Equivariance Loss $L_E({x_d, k})$ : Keypoint의 일관성을 보장하기 위한 loss입니다. 원본 이미지에서 검출된 keypoint는 해당 이미지를 임의로 변환을 하고 다시 keypoint를 검출하고 역변환 했을 때와 동일해야 된다는 내용.
- $x_{T(d)} = T(x_d)$가 이상적인 상황.

- Key Point Prior Loss $L_L(x_d, k)$ : Keypoint가 서로 겹치지않기 위한 Loss (평면에서 keypoint 끼리 거리가 너무 가까우면 안 되며, z 값은 비슷해야 한다는 조건)
- 20개의 키포인트가 얼굴 정보를 골고루 담도록 키포인트 쌍의 거리가 너무 가까우면 ( $<\sqrt{D_t}$ ) 벌점을 부여한다
- 키포인트 평면의 깊이를 정렬 (키포인트 평균 $z$값이 목표 $z_t$에 벗어나면 벌점을 부여한다

- Head Pose Loss L_H : 정확한 고개 방향을 학습하기 위한 Loss. 실제 정답 라벨을 구하기 어렵기때문에 사전학습된 pose estimator (논문 : Fine-Grained Head Pose Estimation Without Keypoints)을 통해 나온 pose를 ground truth \bar{R}_d로 사용. Euler Angle (Yaw, Pitch, Roll)로 분해한뒤 Euler Angles의 합으로 loss를 계산.

- Deformation Prior Loss L_\Delta : \DeltaExpression으로 인해 keypoint가 너무 많이 변하면 안 된다는 제약을 주는 loss입니다.

6개의 각 loss에 대한 weight는 10, 1, 20, 10, 20, 5로 설정했다.
Experiments
Dataset
VoxCeleb2 중 bit-rate가 높은 280K의 데이터와 TalkingHead-1KH dataset을 사용했습니다.
Training
Adam Optimizer와 Learning Rate : 0.0002를 사용해서 256x256 image로 100 epoch 학습한 뒤 512x512 image로 10 epoch 동안 fine-tuning 했다.
Result
- Talking Head Image Synthesis : 평가 지표로나, 정성적으로나 기존 sota 모델들보다 좋은 성능을 보였다.


- Neural Talking Head Video Conferencing : 기존 영상통화는 bandwidth사용량이 큰데 본 논문에서 제시한 방식은 사람의 얼굴 움직임을 간결한 표현으로 압축할 수 있기 때문에 활씬 적은 데이터만으로도 자연스러운 얼굴 영상을 재생할 수 있다.

- Ablation Study
- Direct pred. vs. 2 step pred : 본 논문에서는 Canonical Keypoint를 예측하고 $R, t, \delta$를 예측하는 2 step pred를 진행했는데 네트워크가 바로 최종 Keypoint를 예측하고 Head pose loss와 Deformation Loss가 없는 Direct Keypoint Prediction은 사용자가 고개방향을 제어할 수 없다는 치명적인 단점이 있다. 2 Step Pred는 사용자가 고개 방향을 가능하게하고 성능까지 더 우수하다.
- 2D warp vs. 3D warp (본 논문) : 본 논문에서 사용했던 3D Warping의 성능이 더 우수하다. 깊이 축의 정보를 보존해야 고개 회전할 때나 시점 변경 시 정보 손실이 적음
- Keypoint 개수 (본 논문) : Keypoint K가 많을 수록 디테일 & 정확도 증가. 논문은 K를 20으로 선택.

결론
논문의 기여점 :
- 단 한 장의 source image와 driving video만으로도 자연스럽게 말하고 움직이는 얼굴 영상을 생성할 수 있는 one-shot 합성 기법을 제안,
- 별도의 3D 그래픽스 모델 없이도 유연하고 자유로운 시점 제어(free-view control)를 구현,
- 영상 전체를 전송하지 않고 head pose와 expression deformation 정보만 전송하기 때문에 bandwidth를 줄임
한계점 :
Occlusion가 클 때 성능이 안 좋다는 한계점. (Figure 14 : 손이 가려질 때 Generator가 좋은 성능을 보이지 못함)
