[2025-2] 김지원 - From Transcripts to Insights:Uncovering Corporate Risks UsingGenerative AI
논문 정보: Kim, A., Muhn, M., & Nikolaev, V. (2023). From transcripts to insights: Uncovering corporate risks using generative ai. arXiv preprint arXiv:2310.17721.
논문 링크 : https://arxiv.org/pdf/2310.17721
전세계적 정치적 불안정, 기후 불확실, 그리고 갑작스러운 기술 변화의 시대에 기업들은 전통적 금융 평가들이 의미가 없어진 다양한 리스크들을 직면하고 있다.
이 연구는 생성형 AI 기술과 리스크 평가 방법론 사이의 갭을 메우기 위해 진행되었다.
즉 LLM의 이러한 기업 리스크들의 치명적인 측면들을 감지하고 분석하는 잠재성을 평가하고자 한다.
최근 LLM 기술을 활용해서 저자는 AI의 복잡한 기업 리스크 환경을 파악하는 능력을 확인해보고자 하며 궁극적으로 주주들이 정보에 기반한 결정을 하도록 도울 수 있다.
또한 최근 연구에서 기업 측 자료의 텍스트 분석을 통한 리스크 평가가 주목받고 있다(Hassan et al. 2019,2021; Chava et al. 2022, Sautner et al. 2023).
이 연구들의 주목할 특징은 dictionary-based bigram (n-gram) 빈도들을 활용하여 다양한 리스크 타입을 quantify한다는 점이다.
하지만 최근 AI의 발전은 더 깊은 언어에 대한 이해를 보이며 더 풍부한 정보를 추출할 수 있다.
LLM이 기업 리스크 분석에 매력적인 이유는 두 가지가 있다.
- 기존 전통적 방법과 달리 다양한 문서 집합에서 훈련되었기 때문에 일반적인 지식을 활용할 수 있음. 그리고 이는 기업이 배포한 자료에서 리스크를 명확하게 명시하지 않고 있기 때문에 기존 모델들에 비해 더 효과적임
- LLM은 추출된 정보를 일관성 있고 이해하기 쉬운 서술로 종합하여, 정량적 평가뿐만 아니라 이를 뒷받침하는 설명까지 제공함
예시로 SKT를 보면 기존 전통적 기법과 GPT가 분석한 방식에 차이가 있음을 확인할 수 있다.

무엇이 차이를 만들었을까? 2018년 쯤 전세계적으로 휴대폰 단말기 계약과 통신 서비스의 묶음 판매 규제에 관해 논의되었다.
2018년 SKT의 어닝콜에서 애널리스트가 적극적으로 묶음 판매들에 대해 질문했다.
하지만 transcript에서는 어떠한 정치적 또는 규제 리스크를 명확하게 포함하지 않았고 이는 bigram에 의해 포착되지 않았다.
반면 GPT(GPT3.5-Turbo)는 “the separation of handsets and telecom services”(단말기와 통신의 분리)를 잠재적 규제 불확실성으로 판단하고 이러한 이슈에 대해 설명했다.
저자는 본 연구에서 2018년 1월부터 2023년 3월까지의 실적 컨퍼런스 콜 녹취록에서 얻은 관련 위험 관련 정보를 추출하여 GPT 기반 리스크 노출 측정이 기존 방법에 비해 주식 시장 불확실성과 관련 경제적 결과 예측에 어떤 차이가 있는지 분석한다.
특히나 저자는 기업 주주에게 가장 중요한 기업 리스크에 집중했다: 정치적 리스크, 기후적 리스크 그리고 AI 관련 리스크.
(AI리스크는 AI에 너무 과도한 투자를 하고 있다~라는 리스크를 의마함)
위 3가지 리스크에 대해 저자는 2가지 평가 기법을 사용: (1) 리스크 요약 (2) 리스크 평가
리스크 요약: GPT에게 오직 문서 내용에 집중하고 어떠한 판단(주관성)도 만들지 말라고 지시
리스크 평가: 문서의 전체 맥락과 LLM의 일반 지식을 결합하여 평가를 내리도록 함
이렇게 정리된 요약본을 가지고 저자들은 단순하게 리스크 요약 또는 평가의 길이에 전체 transcript 길이 대비 비율을 가지고 수치화했다.(비율이 높을 수록 리스크 노출도가 높은 것임)

여기서 i는 회사, t는 분기(quarter), $K_{it}$는 chunk를 의미한다.
정치적 그리고 기후적 리스크들의 시계열은 bigram 기반 평가와 함께 움직였다.
저자는 추가로 리스크 평가의 변동성에 대한 분석을 진행했는데 전체 변동성에서 시간 효과, 산업 효과, 그리고 시간x산업 효과가 존재함을 확인했다.
이들(매크로 이벤트)은 전체 변동성에서 10-15%를 설명하고 개별 기업의 리스크는 리스크 변동의 85-90%를 설명한다.
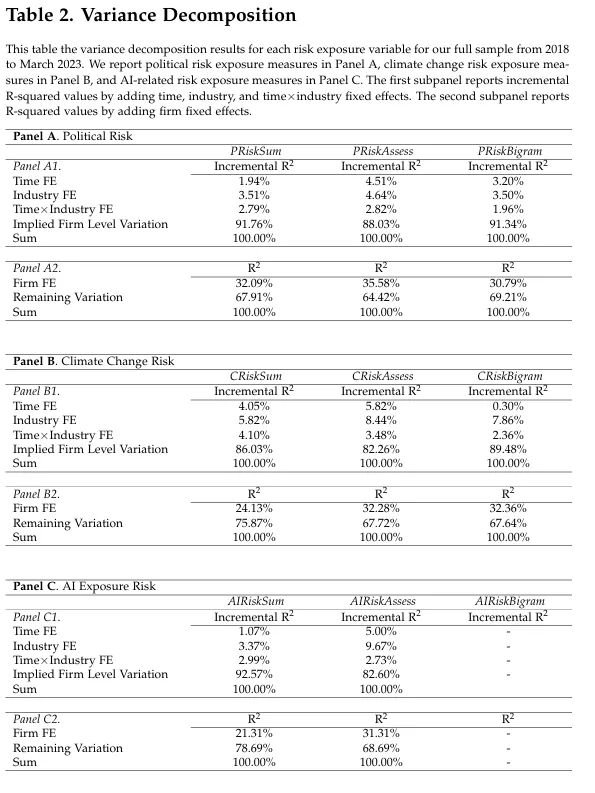
추가적으로 기업레벨 고정효과를 포함함으로써 잔차 분산에 집중해봤다.
논문에서 기업 고정 효과는 21-35%의 기업 레벨 분산을 설명하고 65-79%의 나머지 분산은 시간에 따라 변동하는 것으로 밝혀졌다.
저자는 해당 연구의 리스크 평가가 (1) 옵션 가격에서 파생된 내재된 변동성과 (2) (Loughran and McDonald 2014에서 언급된) 인지된 비정상적 변동성을 잘 예측하는 지를 보고 싶었다.
이때 인지된 비정상 변동성: Post-Call RMSE와 Pre-Call RMSE의 비율
Post-call RMSE는 컨퍼런스 콜 이후 6~28일 후 거래일 동안 시장 모델이 추정한 시장 잔차로부터의 RMSE 값
시장 모델: $$r_{it} = \beta_0 + \beta_1 r_{mt}+\epsilon_{it}$$
$r_{it}$는 i종목의 t일 주식 수익률, r_mt는 t일 시장 수익률
반대로 컨퍼런스 콜 이전 256~6일 간 시장 모델이 추정한 RMSE값

정치& 기후 측면에서 GPT 기반 리스크 평가는 주식 가격 변동성과 높은 상관관계를 보였음 저자가 제안한 2가지 변동성 지표에도 높은 관련성을 보였다.
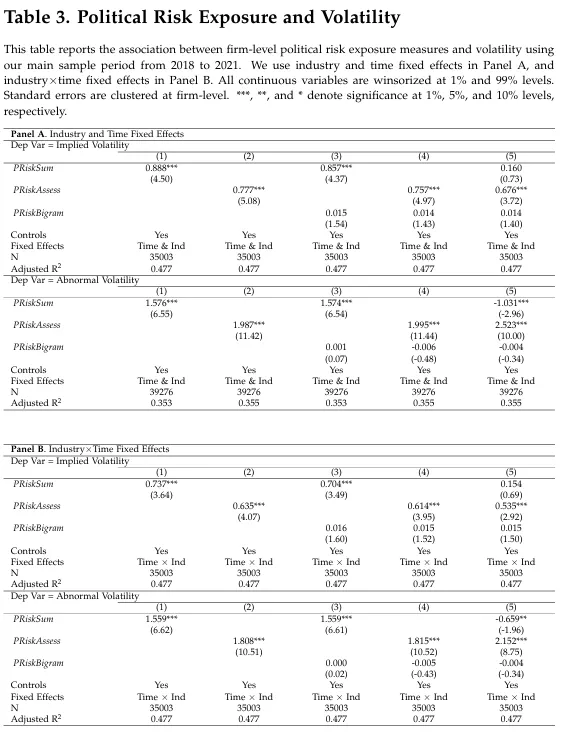

(1),(2)는 모두 GPT 기반 측정 방법, (3), (4)는 bigram 기반 리스크 측정을 추가한 회귀식이다.
(이를 통해 GPT 기반 측정은 bigram 기반 측정이 설명하는 정보를 포함한다고 할 수 있음)
더 중요한 것은 저자의 GPT 기반 측정을 다른 것들과 비교할 때 "리스크 평가"가 "리스크 요약"보다 정치적 & 기후적 리스크에서 더 좋은 퍼포먼스를 보인다.
이는 AI가 생성한 인사이트들이 숨겨진 기업 리스크를 발굴하는데 유용하다는 것을 내포한다.
저자는 또한 GPT가 훈련되지 않은 기간(out-of-sample) 기간에 대해 실험을 진행했다.

샘플의 수가 적긴하지만 강한 robustness를 발견했다.
즉 사후 지식에 의해 결과가 영향받지 않음을 주장함
(Out-of-sample 테스트 통과 → GPT가 "외워서" 답한 것이 아니라 진짜 분석 능력을 보여줌)
반면, AI 관련 리스크로 넘어가면 AI 리스크가 주식 시장 변동성을 예측하는 증거를 발견하지 못했다.

아마 2018-2021년까지 데이터 주 60%의 데이터가 AI risk에 대해 거의 NA값을 리턴했기 때문일 것이라고 저자는 설명했다.
(하지만 최근 2년으로 국한하면 변동성 설명에 유의한 결과를 보임)
GPT 기반 위험 측정치들의 유효성을 확립한 후, 이제 저자는 각 위험 노출의 결과로 변화할 것으로 예측되는 기업들의 행동에 주목했다.
첫번째로, 저자는 "리스크 측정이 자본 투자를 설명할 수 있는가?"에 대해 질문을 던졌다.
자본 투자 공식:
$$K_t=K_{t-1}\cdot(1-\delta)\cdot(1+\rho_t)+CapEx_t$$
$\delta$는 감가 상각 비율, $\rho_t$는 인플레이션 비율(FRED)
즉 t시점 자본 투자 강도는 $\frac{CapEx_t}{K_{t-1}}$로 측정할 수 있다.
이론적으로 리스크가 높은 기업들은 높은 재무 비용들을 경험하고(높은 자금조달 비용을 경험) 기다릴 수 있는 옵션을 가치있게 여긴다.
(그러므로 투자에 대한 결정을 내릴 가능성이 낮다.)
하지만 기술 관련 이슈와 관련해서는 효과가 불분명한데 그 이유는 AI 문제는 새로운 기술에 상당한 투자를 필요로 하기 때문이다.
(따라잡힐까봐 투자하자 마인드)
정치적 그리고 기후적 리스크 노출은 투자와 부정적인 연관을 보이는 반면 AI 리스크는 긍정적인 관계를 보였다(2022-2023)
추가적으로 (1) 정치적 위험이 올라가면 로비활동이 증가하고 (2) 기후 위험이 증가하면 친환경 특허 출원이 증가하며 (3) AI 위험이 증가하면 AI 관련 특허 출원이 증가함을 발견했다.

변수 계산 디테일:
로비 활동: Lobby금액이 0이상이면 lobbying indicator는 1 그렇지 않으면 0으로 측정
친환경 특허 출원: USPTO(United States Patent and Trademark Office)로부터 데이터 수집해서 확인. 해당 분기에 Green Patent가 1이상 등록되면 1 아니면 0으로 측정
(AI 특허 출원도 비슷하게 진행)
이는 기업들이 각 위험에 맞는 구체적 대응책을 취한다는 실증적 증거이다.
이 논문의 학술적 기여
- AI의 경제적 유용성 입증
- 기업 공시 기반 위험 측정 방법론 개선
- 일반 AI 지식의 가치 입증
모델 구현 세부 사항

저자는 GPT의 최대 토큰 수는 4000인 반면 transcripts는 평균적으로 7000이기 때문에 몇가지 파트들로 청크를 쪼갰다.
청킹은 GPT의 퀄리티를 높이는데 이는 모델이 긴 문서를 다룰 때 디테일한 요약을 생성하는데 어려움을 겪기 때문이다.
(구체적으로는 2000 토큰을 input text로 넣고 나머지를 출력 토큰 수로 넣음)
청크 퀄리티를 높이기 위해 저자는 transcript를 presentation과 Q&A 세션으로 나눴으며,
presentation 파트에서는 같은 executive의 발표를 쪼개는 것을 지양했다.
(비슷하게 동일한 애널리스트의 질문을 끊지 않았음)
마지막으로 리스크와 관련된 정보가 부재하다면 NA로 출력하도록 지시했다.
프롬프트 관련 내용
리스크 요약:
- 외부 정보 소스를 무시하도록 지시
리스크 평가:
- 반대로 (일반 지식을 활용한) 추론과 함께 판단을 하라고 함
공통적인 부분:
- 입력 텍스트가 어닝 콜 transcript에서 발췌되었음을 명시하는 컨텍스트를 모델에 제공
- 각 리스크에 대한 설명과 리스크 노출에 대한 이해와 관련된 몇 가지의 예시 질문들 제공