[2025-1] 박서형 - UNIFORMER
https://arxiv.org/pdf/2201.04676
0. Abstract
고차원 비디오로부터 풍부하고 다중 스케일의 시공간 의미를 학습하는 것은 어려운 과제이다. 비디오 프레임 간에 지역적 중복이 크고, 전역적인 의존성이 복잡하기 때문이다. 이 연구 분야의 최근 발전은 주로 3D CNN과 vision transformer에 의해 이루어졌는데 3D CNN은 멀리 있는 프레임 간 global 정보는 잘 보지 못하고 vision transformer는 가까운 프레임 사이의 지역적인 중복은 잘 제거하지 못한다. 본 논문은 위 두 방식을 적절히 섞은 UNIFORMER라는 모델을 제안하는데 이 모델은 얕은 layer에서는 3D 합성곱처럼 지역 정보를 잘 처리하고 깊은 layer에서는 트랜스포머처럼 global 관계를 잘 파악한다. 이 모델을 이용하여 ImageNet-1K라는 기본 데이터셋 하나만 사용해 학습했는데도 Kinetics-400/600이라는 유명한 비디오 테스트셋에서 82.9%/84.8% 정확도 달성했고 심지어 다른 최신 모델보다 연산량은 10배나 적게 드는 성과를 보였다.
1. Introduction
spatiotemporal representations(시공간 표현)을 학습하는 데에는 아래와 같은 주요한 두 가지 도전 과제가 있다.
- 인접한 프레임 간 움직임이 미세하기 때문 비디오는 많은 시공간적 중복(redundancy)을 포함 -> 너무 많은 정보량
- 비디오는 복잡한 시공간적 의존성(dependency)을 포함 -> 멀리 있는 프레임들 사이에 중요한 관계를 가질 수 있는데 이런 관계는 파악하기가 어려움
이때 3D CNN은 receptive field 내에서 정보를 처리하기 때문에 local feature를 잘 파악하는 동시에 local redundancy(중복)을 잘 제거할 수 있지만 global 관계를 포착하는데는 약점을 보인다. 반면 vision transformer는 global feature는 잘 포착하지만 연산량이 너무 많고 local redundancy(중복)을 잘 제거하지 못한다는 단점을 가진다.
UNIFORMER 모델은 Dynamic Position Embedding (DPE), Multi-Head Relation Aggregator (MHRA), Feed-Forward Network (FFN)의 세 가지 모듈로 구성되어 있다. 그리고 이 모델의 가장 주요한 특이점은 relation aggregator인데 이는 아래와 같은 특징을 가진다.
- 모든 계층에서 self-attention을 사용하는 대신, 우리의 관계 집계기는 중복과 의존성을 각각 처리
- 모든 계층에서 시공간 컨텍스트를 함께(jointly) 인코딩
- UniFormer 블록을 계층적으로 점진적으로 통합
UNIFORMER는 다른 모델에 비해 10배 작은 GFLOPs만을 사용하였고 Something-Something V1/V2 데이터셋에선 SOTA를 달성하였다.
2. Method
2.1 OVERVIEW OF UNIFORMER BLOCK
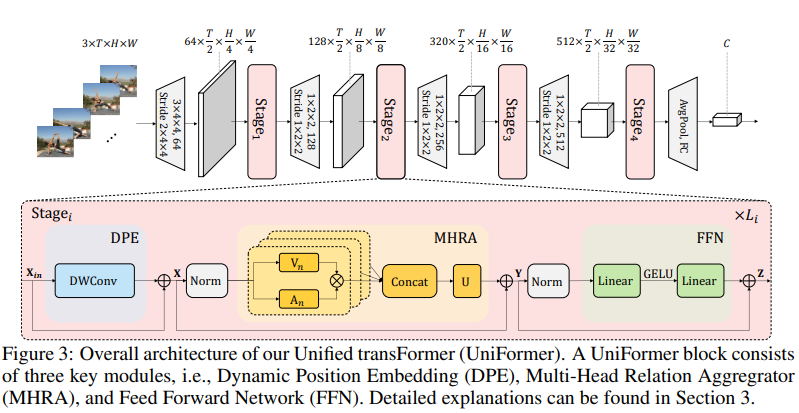
UNIFORMER 블록은 Dynamic Position Embedding (DPE),Multi-Head Relation Aggregator (MHRA),Feed-Forward Network (FFN)의 세 가지 모듈로 구성되어 있는데 계산 방식은 다음과 같다.

DPE를 통해 모든 토큰에 3D 위치 정보를 동적으로 통합하고 MHRA를 통해 각 토큰이 주변 문맥 토큰들과 정보를 집계(aggregation)하도록 하며 FFN을 통해 각 토큰을 개별적으로 강화(pointwise enhancement)한다. 이때 입력은 텐서 Xin ∈ ℝ^{C×T×H×W} (채널×시간×높이×너비)이다.
2.2 MULTI-HEAD RELATION AGGREGATOR
1) Local MHRA
얕은 layer에서는 local한 feature를 잡는데 집중하기 위해 3D CNN과 유사한 방식으로 동작하는 모듈을 사용한다.
- 입력 flatten : X ∈ R^(C×T ×H×W ) -> X ∈ R^(L×C)
- linear transform : Vn(X)∈RL×d (d=C/N) -> 토큰별로
- local learnable parameter matrix 생성 : Anlocal(Xi,Xj)=ani−j
- context vector 생성 : Rn(X)=An⋅Vn(X)
- MHRA(X)=Concat(R1,R2,...,RN)⋅U -> U도 학습 가능한 파라미터

여기서 Rₙ(·)는 n번째 head의 relation aggregator(RA)인데 각 RA는 context encoding( Vₙ(X) ∈ ℝ^{L×(C/N)}), affinity learning( Aₙ ∈ ℝ^{L×L})의 두 단계로 구성되어 있다.
2) global MHRA
깊은 layer에서는 전체 비디오 클립 내에서 장기적인 토큰 간 의존성(capturing long-term token dependency)을 포착하는 데 집중하기 위해 self-attention과 유사한 구조를 따른다. global MHRA는 큰 구조는 local MHRA와 동일하지만 affinity vector를 다른 방식으로 구하게 된다.

이때 는 크기의 전역 3D 튜브 내의 임의의 토큰이고 과 Kn(⋅)K_n(·)는 서로 다른 두 개의 선형 변환이다. 기존 비디오 Transformer들은 계산량이 너무 많아서 어텐션 분해 (attention factorization)를 해서 Spatial Attention과 Temporal Attention을 따로따로 적용했다. 이때 Temporal Attention은 시간축으로 비교해서 같은 위치의 토큰만 가지고 attention을 하는 것이고 Spatial Attention은 공간축으로 비교해서 같은 시간의 토큰만 가지고 attention 연산을 한다. 그런데 UNIFORMER가 하는 시공간을 함께(jointly) 고려한 attention은 모든 토큰 쌍에 대해 attention 가중치를 계산한다.

2.3 DYNAMIC POSITION EMBEDDING
absolute, relative position embedding은 이 모델에 바로 적용하기엔 문제가 많아 conditional position encoding을 변형한 Dynamic Position Embedding (DPE)를 사용한다.

DPE는 간단한 3D Depthwise Convolution (DWConv) 으로 위치 정보를 학습한다.
2.4 MODEL ARCHITECTURE
UNIFORMER는 UniFormer 블록들을 계층적으로 쌓아 네트워크를 구성한다. 이때 이 모델은 총 4개의 stage로 구성되어 있으며,
각 stage의 채널 수는 각각 64, 128, 320, 512이다. 본 논문은 각 stage에 들어가는 UniFormer 블록 수에 따라 두 가지 모델 변형(variants)을 제공하는데 각각 UniFormer-S: {3, 4, 8, 3}와 UniFormer-B: {5, 8, 20, 7}이다. 이때 첫 번째와 두 번째 stage에서는 local MHRA를 사용하고 tube 크기는 5×5×5( T × H × W ), 헤드 수 은 각 stage의 채널 수와 동일하게 사용한다. 그리고 정규화로는 BatchNorm을 사용한다. 그리고 세번째, 네번째 stage에선 global MHRA를 사용하며 헤드 차원은 64이고 정규화로는 LayerNorm을 사용한다.
DPE의 커널 크기는 이고 (T×H×W), 모든 FFN의 확장 비율(expand ratio)은 4이다.
첫 번째 stage 앞에는 커널 크기와 스트라이드를 가지는 convolution을 적용하여공간 및 시간 차원을 동시에 downsample한다. 나머지 stage들 앞에는 커널, 스트라이드의 convolution을 적용하여 spatial 차원만 downsample한다. 마지막으로, spatiotemporal average pooling과 fully connected layer를 통해 최종 예측 값을 출력한다.
3. Experiment
3.1
1) Kinetics-400, Kinetics-600
: 더 적은 계산량으로 비슷하거나 더 나은 성능

2) Something-Something V1 & V2
: 새로운 SOTA를 달성

3.2 Ablation Study
1) Does transformer-style FFN help?
: non linearity를 추가해주는 역할 -> MobileNet보다 성능 우수
2) Is joint or divided spatiotemporal attention better?
: joint를 해준 경우 해주지 않았을 때보다 성능 자체도 우수하고 transfer learning을 했을 때 지속적인 성능 향상을 보임

3) Does dynamic position embedding matter to UniFormer?
: DPE를 사용하면 ImageNet과 Kinetics-400에서 top-1 정확도가 각각 0.5%, 1.7% 상승
4) How much does local MHRA help?
: LLGG 조합에서 가장 우수한 성능 보임

3.3 Visualization
: Grad-CAM이라는 기법으로 모델이 가장 주목한 부분을 히트맵으로 표현한 영상을 보면 LLGG 모델이 주요한 축구공, 스케이트보드 같은 정보에 집중하여 판별을 내렸다는 걸 알 수 있다.
