[2025-2] 박지원 - GPTQ
논문) https://arxiv.org/abs/2210.17323
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Generative Pre-trained Transformer models, known as GPT or OPT, set themselves apart through breakthrough performance across complex language modelling tasks, but also by their extremely high computational and storage costs. Specifically, due to their mass
arxiv.org
1. GPTQ란
GPTQ란, GPT 같은 거대 생성형 변환 모델(Generative Pre-trained transformer)이 엄청난 계산 및 저장 비용이라는 한계점을 해결하기 위해 제시된 방법론이다. 'one-shot 가중치' 양자화를 활용하는 방법론으로, 다시 학습시킬 필요 없이 한 번에 가중치(모델 내부의 숫자들)를 압축하는 방식이다. 근사 2차 정보( 모델의 가중치를 양자화할 때, 단순히 가중치의 값만 사용하는 것이 아니라, 그 가중치가 모델의 전체적인 동작에 얼마나 중요한 영향을 미치는지에 대한 정보를 함께 고려하는 것을 의미 ) 를 기반으로 높은 정확도를 유지하면서, '양자화'를 통해 효율성을 높이는 기법이다. 약 1750억 개의 매개변수를 가진(그래서 학습, 추론하는 데만 수십 GPU가 필요한) GPT 모델을 4시간 만에 양자화하는 데 성공했고, 각 가중치당 비트 수를 3~4비트로 축소시키면서 단일 GPU에서의 실행을 가능하게 한 바 있다. 이는 통해 원래 방식 대비 최대 4.5배 빠른 추론 속도를 보여준 것.
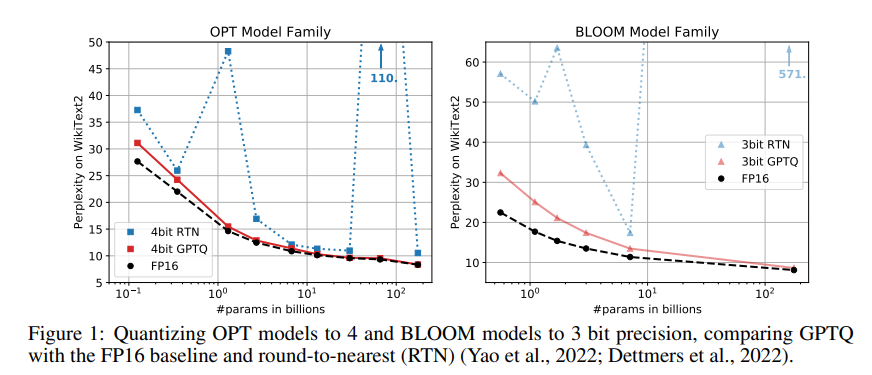
2. 기존 양자화 방법의 한계점
기존에도 모델을 압축하는 기술들은 있었지만, gpt 모델처럼 규모가 크고 복잡한 모델에는 적용하기 어려운 한계점이 있었다. 특히, 수십억 개의 매개변수를 가진 모델의 경우, 정확도를 유지하려면 모델을 다시 학습시켜야 했는데, 이 과정이 엄청나게 비싸고, 용량이 많이 필요했다. 학습 없이 한 번에 압축하는 '사후 양자화( post-training quantization)' 방법도 있었지만, 이 역시 대규모 모델에서는 정확도가 크게 떨어지는 문제가 있었다. 그래서 GPTQ는 기존 OBQ( optimal Brain Quantization) 방법을 기반으로 했지만, 가중치를 '임의의 순서'로 양자화해도 성능 저하가 크지 않다는 인사이트를 통해, 계산 효율성을 크게 높이는 개선방안을 적용했다.

3. 구체적 개선점
- 1단계: 임의 순서 통찰 (Arbitrary Order Insight): 기존 OBQ는 오류가 가장 적게 발생하는 가중치부터 양자화하는 '탐욕적인 순서'를 사용했다. 하지만 GPTQ는 가중치를 임의의 순서로 양자화해도 성능에 큰 차이가 없다는 점을 알아냈고 이는 대규모 모델에서 계산량을 크게 줄이는 핵심 아이디어로 작용했다.

- 2단계: 지연 배치 업데이트 (lazy batch-updates): 양자화과정에서 발생하는 '메모리 접근 병목 현상'을 해결하기 위해 업데이트를 한꺼번에 처리하는 '지연 배치' 방식을 도입했다. 덕분에 GPU활용도가 높아져 실제 모델 양자화속도가 보다 빨라졌다.
- 3단계: 촐레스키 재구성 (Cholesky Reformulation): 모델이 커질수록 계산 과정에서 수치적인 불안정성이 발생하는 문제가 있었다. GPTQ는 이 문제를 해결하기 위해 '촐레스키 분해'라는 수학적 기법을 활용하여 알고리즘의 안정성을 확보했고 이로 인해 대규모 모델에서도 오류 없이 양자화를 수행할 수 있게 되었다.

4. 성능
실험 결과: 소규모 모델 및 대규모 모델에서의 성능 검증
- ResNet18, ResNet50과 같은 소규모 이미지 모델에서도 최신 양자화방법들과 비슷한 성능을 보여주었다.
- 대규모 언어 모델인 OPT 및 BLOOM 모델군에 대한 실험에서도 GPTQ는 RTN(Round-to-Nearest, 반올림) 방식보다 훨씬 뛰어난 성능을 보였다. 또 OPT-175B 모델을 4비트로 양자화했을 때 RTN 방식은 정확도가 크게 떨어졌지만, GPTQ는 거의 손실이 없었다!
- 특히, 1750억 개의 매개변수를 가진 모델을 단 몇 시간 만에 양자화할 수 있는 뛰어난 런타임을 보여줬다.

5. 실제 적용 사례 및 속도 향상
gptq로 양자화된 opt-175B 모델은 단일 80GB A100 gpu에 탑재될 수 있었는데, 이는 fp16(원래)버전이 5개의 80GB gpu를 필요로 했던 것에 비하면 엄청난 발전이다. 또 언어 생성 작업에서 gptq는 fp16대비 최대 4.5배의 지연 시간 감소를 달성했다. 특히 메모리 대역폭에 의해 제한되는 행렬-벡터 곱셈 연산에서 효과적이었다.

6. 추가적인 활용 가능성: 극단적 양자화 및 그룹화
gptq는 다양한 양자화그리드와 호환되며, 각 가중치를 개별적으로 양자화하는 대신 특정 개수의 가중치를 묶어서(그룹화) 양자화하는 '그룹화(grouping)' 기법과 결합하여 정확도를 더욱 향상시킬 수 있었다. 결과적으로 평균 2비트 수준의 극단적인 양자화에서도 합리적인 성능을 달성하여, 앞으로 더 낮은 비트 폭으로도 모델을 압축할 가능성을 입증했다.
7. 결론 및 향후 과제
gptq는 대규모 언어 모델을 정확하게 압축하여, 이 모델들을 더 많은 연구자와 개발자가 쉽게 접근하고 활용할 수 있도록 만들었다는 점에서 혁신적이다. 또 gptq는 '계산량 감소'가 아닌 '메모리 이동 감소'를 통해 속도 향상을 이루어냈으며, 활성화 양자화(activation quantization)는 아직 고려하지 않은 만큼, 앞으로의 연구를 통해 개선될 수 있는 여지가 있다.