CV
[2025-1] 전윤경-Oscar: Object-Semantics Aligned Pre-trainingfor Vision-Language Tasks
rachel2003
2025. 5. 23. 10:23
Oscar: 이미지 내에서 탐지된 객체 태그(object tags)를 anchor points로 활용하여 의미 정렬 학습을 크게 용이하게 하는 학습 방법
- 학습 샘플(tuple): 단어 시퀀스(word sequence), 객체 태그 집합(set of object tags), 이미지 영역 특징 집합(set of image region features)
- 650만 쌍으로 구성된 대규모 V+L 데이터셋으로 사전학습
- 7개의 V+L 이해 및 생성 과제에 대해 미세조정 및 평가를 수행

기존 VL 학습 데이터: 이미지-텍스트 쌍
기존 VLP방법의 문제점
- 시각 임베딩의 모호성: Faster R-CNN로 과도하게 샘플링된 영역, 중첩
- weakly-supervised learning : 본질적으로 이미지 내 영역이나 객체와 텍스트 사이에 명시적으로 라벨된 정렬 정보가 없음.

Pre training
이미지- 텍스트 쌍: 단어-태그-이미지 (w, q, v) 삼중항 으로 표현
- w: 텍스트의 단어 임베딩 시퀀스
- q: 이미지에서 탐지된 객체 태그(object tags)의 단어 임베딩 시퀀스(텍스트 형태)->앵커 포인트(anchor points)로 도입
- v: 이미지의 영역 벡터 집합
q, w : 사전학습된 BERT 모델을 사용해 q와 w 간 정렬 쉽게 식별
시각 공간에서는 애매하게 표현될 수 있는 이미지 객체들-> 언어 공간에서 구별 가능한 실체로 연결(grounding)하는 학습
K개의 객체 영역이 있는 이미지
- Faster R-CNN 이용해 각 영역 시각 의미 (v⁰, z)로 추출[영역 특징: v⁰, 영역 위치 : z]
- v⁰와 z를 연결(concatenate)
- 선형 투영(linear projection)-> 단어 임베딩과 동일한 차원 크기의 벡터 v로 변환

입력
x: 텍스트와 이미지 간 표현을 구분하는 modality view
x': 입력이 표현되는 두 가지 서로 다른 의미 공간을 구분하는 dictionary view

dictionary 관점: Masked Token Loss (MTL)
이산 토큰 시퀀스 h = [w, q]
- 입력 토큰 h 내의 각 토큰을 15% 확률로 무작위 마스킹-> 마스킹된 토큰 h_i는 특별 토큰 [MASK]로 대체
- 주변 토큰 h_i와 모든 이미지 특징 v를 기반으로 마스킹된 토큰을 예측
- negative log-likelihood를 최소화하는 방식

modality 관점: Contrastive Loss (대조 손실)
h' = [q, v]: 이미지 모달리티, w:언어 모달리티
- 50% 확률로 q를 무작위로 선택된 다른 태그 시퀀스로 교체하여 "오염된(polluted)" 이미지 표현 집합을 샘플링
- 인코더 출력의 특별 토큰 [CLS] ( (h', w)의 융합된 비전-언어 표현) -> 완전 연결층(FC)을 이용한 이진 분류기 f를 적용하여 원본 이미지 표현(y=1)인지 오염된 것(y=0)인지 예측

전체 사전 학습 목표

- 각각의 손실은 독자적인 관점에서 대표적인 학습 신호를 제공
- 전체 손실이 기존 VLP 방법보다 훨씬 간단함에도 실험에서 우수한 성능
Experiment
650만 개의 공개 텍스트-이미지 쌍 코퍼스에서 사전학습
OscarB와 OscarL: BERT base( H=768)와 BERT large(H=1024)의 파라미터로 초기화
- 이미지-텍스트 검색(Image-Text Retrieval): 이미지가 주어졌을 때, 관련 텍스트를 찾거나, 텍스트가 주어졌을 때 관련 이미지 찾기
- 이미지 캡셔닝(Image Captioning): 이미지 내용 문장 생성
- 신규 객체 캡셔닝(Novel Object Captioning, NoCaps) : 학습 데이터에 없는 새로운 객체 포함 이미지 내용 문장 생성
- 시각 질문 응답 (Visual Question Answering, VQA) : 이미지와 자연어 질문이 주어졌을 때, 질문에 맞는 정확한 답변을 선택하거나 생성
- GQA (General Question Answering): VQA와 유사하지만, 좀 더 복잡한 추론 능력
- NLVR2 (Natural Language Visual Reasoning):두 이미지와 자연어 문장이 주어졌을 때, 문장이 두 이미지 쌍에 대해 참인지 거짓인지를 판단
- 신규 객체 질문 응답 (Novel Object VQA): 훈련에 없던 새로운 객체에 대한 질문에 답

- 대부분 과제에서 기존 대형 모델을 크게 능가

- feature 공간을 t-SNE를 사용해 2차원 맵으로 시각화
- intra class: 객체 태그의 도움으로 두 모달리티(이미지와 텍스트)에서 동일한 객체 간의 거리가 크게 줄어듦
- inter class: 관계가 있는 객체 간의 거리가 줄어듦

- Faster R-CNN이 탐지한 정확하고 다양한 객체 태그를 사용하여 기준선보다 더 상세한 이미지 설명을 생성
Abalation study
객체 태그의 효과

- 기준선 (태그 없음): 모델을 이전의 VLP 모델과 동일하게 만들어, 태그 정보를 전혀 사용하지 않음
- 예측된 태그: COCO 데이터셋으로 학습된 기성 객체 탐지기를 사용해 객체 태그를 예측
- 정답 태그: COCO 데이터셋에서 제공하는 정답 태그를 사용 (성능 “상한선” 역할)
- 객체 태그를 활용한 미세 조정 학습 곡선이 태그 없이 수행한 VLP 방법보다 모든 과제에서 훨씬 빠르고 더 좋은 성능
Attention 상호작용
이미지-텍스트 검색 과제에서 어텐션 마스크를 다양하게 변경하며 미세조정 실험

- 객체 태그를 추가하는 것이 유리함
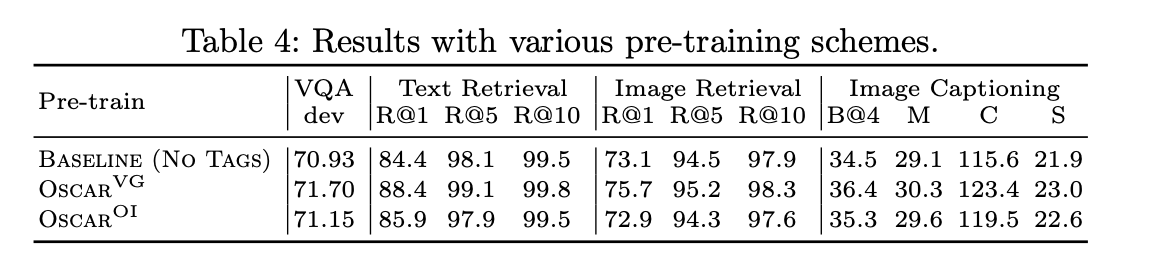
- OscarVG: Visual Genome(VG) 데이터셋으로 학습된 객체 탐지기가 생성한 객체 태그
- OscarOI: Open Images(OI) 데이터셋으로 학습된 탐지기의 태그
Contribution
- V+L 이해 및 생성 과제를 위한 일반적인 이미지-텍스트 표현 학습에 효과적인 강력한 VLP 방법
- 여러 V+L 벤치마크에서 기존 방법을 크게 앞서는 새로운 최첨단 성능을 달성
- 객체 태그를 앵커 포인트로 활용한 교차 모달 표현 학습 및 후속 과제 수행의 효용성에 관한 광범위한 실험과 분석을 제공