[2025-1] 이재호 - Masked Autoencoders Are Scalable Vision Learners
https://arxiv.org/abs/2111.06377 - Kaiming He, Xinlei Chen...
Masked Autoencoders Are Scalable Vision Learners
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we
arxiv.org
# Abstract
이 논문에서는 **Masked Autoencoders (MAE)**가 컴퓨터 비전 분야에서 self-supervised 학습 모델임을 보여줌.
- 마스킹 기반 학습
- 입력 이미지에서 랜덤한 패치를 마스킹하고, 이를 복원하는 방식으로 학습.
- 비대칭적 인코더-디코더 구조
- 인코더: 마스킹되지 않은 부분만 처리하여 효율성을 높임.
- 디코더: 원본 이미지를 재구성하는 가벼운 구조를 가짐.
- 고비율 마스킹(75%)의 효과
- 학습 과정에서 **의미 있는 자가 지도 학습(self-supervised task)**이 형성됨.
- 훈련 속도 3배 이상 향상 & 성능 개선 효과.
- 확장성과 성능
- **대형 모델(ViT-Huge)에서 최고 성능(87.8%)**을 달성 (ImageNet-1K 기준).
- 전이 학습 성능이 지도 학습(supervised pretraining)을 능가.
# 1. Introduction
배경 및 동기
- 딥러닝 모델이 점점 더 많은 데이터와 연산량을 요구
- 최신 모델들은 수억 개의 라벨링된 이미지가 필요하지만, 데이터 확보가 어려움.
- 반면, NLP에서는 자기지도학습(SSL)이 GPT, BERT 등의 모델을 훈련하는 데 성공적으로 적용됨.
- 이미지와 언어의 차이점으로 인해 Masked Autoencoding이 NLP보다 비전에서 발전이 느렸음
- 구조 차이: 기존 컴퓨터 비전 모델들은 주로 CNN을 사용하여 토큰(mask token)이나 위치 임베딩을 쉽게 적용할 수 없음.
- 정보 밀도 차이: 언어는 정보 밀도가 높지만, 이미지는 공간적으로 중복된 정보가 많아 마스킹이 단순하면 학습이 어렵거나 쉬운 문제가 됨.
- 디코더 역할 차이: NLP에서는 마스킹된 단어를 예측하는 것이 의미론적으로 풍부한 정보를 포함하지만, 이미지에서는 단순한 픽셀 복원이기 때문에 표현 학습에 적절한 전략이 필요함.
MAE 핵심 아이디어
- 비대칭적(Asymmetric) 인코더-디코더 아키텍처
- 인코더: 마스킹되지 않은 패치만 처리하여 효율적인 표현 학습 수행.
- 디코더: 마스킹된 영역을 복원하는 가벼운 구조로 설계하여 연산량 감소.
- 고비율 마스킹 적용 (75%)
- 높은 마스킹 비율을 적용하여 학습 난이도를 적절히 조절.
- 중복된 이미지 정보를 줄이고, 더 강력한 특징 표현을 학습하도록 유도.
- 효율적이고 확장 가능한 구조
- 고비율 마스킹으로 인해 훈련 속도를 3배 이상 향상.
- 메모리 소비량 감소, 대규모 모델로 쉽게 확장 가능.

# 3. Approach
1. Asymmetric Autoencoder
- 인코더: 마스킹되지 않은 패치만 처리하여 효율성을 높임.
- 디코더: 전체 이미지를 복원하는 가벼운(lightweight) 구조로 설계.
- 비대칭적 설계 덕분에 연산량 감소 & 대규모 모델 학습 가능.
2. Masking 기법
- 이미지를 비중첩(non-overlapping) 패치들로 나눈 후, 랜덤한 패치들을 마스킹.
- 고비율(75%) 마스킹을 적용하여:
- 단순한 공간적 보간(extrapolation)으로 해결할 수 없게 만듦.(주변 픽셀을 활용하여 해당 픽셀을 채우는 식이 안됨)
- 모델이 보다 의미 있는 표현을 학습하도록 유도.
- 메모리 절약 & 연산 효율성 향상.
3. MAE encoder
- ViT (Vision Transformer) 기반 인코더 사용.
- 오직 마스킹되지 않은 패치만 입력으로 받아 처리 → 전체 이미지의 25%만 사용.
- 마스킹된 패치는 아예 모델에 입력되지 않음 (BERT와 차이점).
- 결과: 메모리 절약 & 더 큰 모델을 학습 가능.
4. MAE decoder
- 디코더 입력 = 인코딩된 보이는 패치들 + 마스크 토큰(mask tokens).
- 마스크 토큰은 학습된 벡터이며, 원래 위치 정보를 복원하기 위해 positional embedding 추가.
- 디코더는 훈련(Pre-training) 시에만 사용 → 최종적으로는 필요 없음.
- 매우 작은 구조(인코더 대비 연산량 <10%)로 설계됨 → 연산량 대폭 감소.
5. Reconstruction target
- 픽셀 단위 복원(Pixel-Level Reconstruction) 수행.
- 디코더의 최종 출력 = 마스킹된 패치들의 픽셀 값 예측.
- 손실 함수: Mean Squared Error (MSE) 사용.
- 픽셀 정규화(Normalization) 기법을 추가하여 표현 학습 성능 개선.
6. Simple implementation
- 마스킹된 패치를 제거한 후, 인코더에 입력.
- Encoding 후, 마스크 토큰을 추가하여 원래 순서대로 정렬 (unshuffle process).
- 디코더에서 전체 패치를 복원.
- Sparse 연산 없이도 간단하게 구현 가능하여 성능과 효율성을 동시에 확보.


# 4. Experiments
MAE는 ImageNet-1K(IN1K) 데이터셋에서 **자기지도 사전 학습(Self-Supervised Pretraining)**을 수행한 후, **지도 학습(Supervised Training)**을 통해 표현 학습 성능을 평가함.
평가는 (i) End-to-End Fine-Tuning과 (ii) Linear Probing 방식을 사용하여 진행되었으며, 모델의 Top-1 검증 정확도를 보고함.

- ViT-L 모델을 지도 학습(Supervised Training)만으로 훈련하는 것은 어렵고, 강한 정규화(Regularization)가 필요함.
- 그러나 MAE를 통한 사전 학습(Pretraining)을 적용하면 Fine-Tuning만으로도 성능이 크게 향상됨.
- 특히, Scratch 학습 시 200 Epoch이 필요하지만, MAE 사전 학습 후 Fine-Tuning 시 50 Epoch만으로도 더 높은 성능 달성 가능.
- 이는 MAE의 사전 학습이 모델의 일반화 성능을 크게 향상시키고, 학습 속도를 단축하는 효과가 있음을 의미함.
4.1 Main properties

- Masking Ratio
- 75% 마스킹 비율이 최적, 특히 Linear Probing에서 중요.
- 기존 BERT(15%)나 다른 비전 연구(20~50%)보다 훨씬 높은 비율 사용.
- Fine-Tuning에서는 마스킹 비율이 성능에 미치는 영향이 적음.

- Decoder Design
- 깊은 디코더는 Linear Probing 성능을 개선하지만 Fine-Tuning에는 영향 적음.
- 1-block 디코더도 Fine-Tuning에서 84.8% 성능 기록.
- 경량 디코더(8 blocks, 512-d) 사용 시 연산량 절감(ViT-L 대비 FLOPs 9%).
- Mask Token
- 마스크 토큰을 인코더에서 제거하면 성능 14% 향상, 학습 속도 3.3배 증가.
- 높은 마스킹 비율(75%)에서는 4배 이상의 속도 증가 가능.

- Reconstruction Target
- 정규화된 픽셀(Normalized Pixels) 복원이 가장 효과적.
- dVAE 토큰 기반 복원은 연산량 증가(40% FLOPs 추가)로 비효율적.
- Data Augmentation
- Cropping-only 증강만으로 충분, 색상 변형(Color Jittering)은 성능 저하.
- Contrastive Learning과 달리, 데이터 증강 없이도 높은 성능 유지 가능.
- Mask Sampling Strategy
- 랜덤 마스킹이 가장 우수, Block-wise 및 Grid-wise 방식은 성능 저하.
- 높은 마스킹 비율에서도 안정적 성능 유지.

- Training Schedule
- 긴 학습이 필요하며, 1600 Epoch까지 성능 지속 증가.
- Contrastive Learning(MoCo v3 등)과 달리, MAE는 학습이 포화되지 않음.

4.2 Comparisons with Previous Results

1) self-supervised learning 과 비교
- MAE는 대형 모델에서도 과적합 없이 확장 가능하며, 모델 크기가 클수록 성능 향상이 두드러짐.
- ViT-H(224 size)에서 86.9%, 448 size에서 87.8% 정확도 달성(IN1K 데이터만 사용).
- 기존 최고 성능(87.1% with 512 size)보다 우수한 결과 기록.
- BEiT 대비 더 정확하고(Simple, Faster), BEiT는 픽셀 복원 시 1.8% 성능 저하 발생.
- dVAE 사전 학습이 필요 없으며, BEiT 대비 3.5배 빠르게 학습 가능.
2) 학습 속도 비교
- MAE는 1600 Epoch을 학습하지만, 기존 방법 대비 전체 학습 시간이 더 짧음.
- 예: ViT-L을 TPU-v3에서 학습할 때,
- MAE: 31시간(1600 epochs)
- MoCo v3: 36시간(300 epochs)
3) supervised learning과 비교
- ViT-L 모델을 IN1K에서 지도 학습 시 성능 저하 발생.
- MAE 사전 학습을 적용하면 대형 모델에서 일반화 성능이 크게 향상됨.
- JFT-300M과 같은 대규모 지도 학습 트렌드와 유사한 경향을 보이며, 모델 크기 확장에 유리.

4.3 Partial fine-tuning

- Linear Probing과 Fine-Tuning의 관계
- Linear probing과 fine-tuning 성능은 강한 상관관계를 보이지 않음.
- Linear probing은 선형적 특징을 평가하지만, deep learning의 강점인 비선형적 특징을 반영하지 못함.
- 이를 보완하기 위해 Partial Fine-Tuning 기법을 연구함.
- Partial Fine-Tuning 실험 결과
- Transformer 한 개 블록만 미세 조정하면 73.5% → 81.0%로 성능 향상.
- 마지막 블록의 절반(MLP sub-block)만 fine-tuning해도 79.1% 기록, linear probing보다 우수함.
- 4~6개 블록을 fine-tuning하면 Full Fine-Tuning에 가까운 성능 도달 가능.
- MoCo v3와 비교
- MoCo v3는 Linear Probing 성능이 높지만, Partial Fine-Tuning 시 MAE보다 성능이 낮음.
- 4개 블록 fine-tuning 시 MAE가 MoCo v3 대비 2.6% 더 높은 성능 기록.
- MAE는 선형적으로 분리하기 어려운(Non-linear) 강한 특징을 학습함.
# Transfer Learning Experiments
1. Object detection & Segmentation
- COCO 데이터셋에서 Mask R-CNN을 Fine-Tuning하여 평가.
- MAE가 지도 학습(Supervised Pretraining)보다 모든 설정에서 더 높은 성능 기록.
- ViT-B 모델: MAE가 2.4점 더 높음 (50.3 vs. 47.9, APbox).
- ViT-L 모델: MAE가 4.0점 더 높음 (53.3 vs. 49.3, APbox).
- 픽셀 기반 MAE가 BEiT보다 더 좋거나 비슷한 성능을 내면서도, 더 단순하고 빠름.
- MAE와 BEiT는 MoCo v3보다 우수하며, MoCo v3는 지도 학습과 비슷한 수준.

2. Semantic segmentation
- ADE20K 데이터셋에서 UperNet을 사용하여 실험.
- MAE 사전 학습이 지도 학습보다 3.7점 높은 성능 향상(ViT-L 기준).
- 픽셀 기반 MAE가 BEiT보다 우수하며, COCO 실험과 일관된 결과.

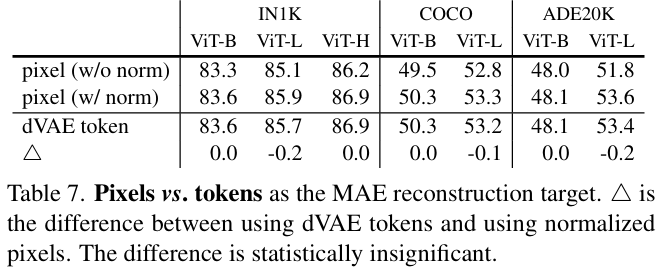
3. Classification tasks
- iNaturalist, Places 데이터셋에서 평가.
- MAE는 모델 크기가 커질수록 정확도가 크게 향상됨(Scaling 효과).
- iNaturalist에서는 이전 최고 성능보다 큰 차이로 성능 향상.
- Places에서는 수십억 개의 이미지로 사전 학습된 기존 모델보다도 MAE가 뛰어난 성능 기록.
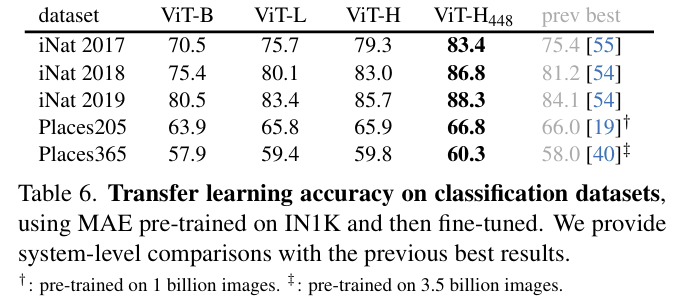
4. Pixels & Tokens
- 픽셀 vs. dVAE 토큰을 비교한 결과,
- dVAE 토큰이 비정규화 픽셀보다 좋지만, 정규화 픽셀과는 유사한 성능.
- 즉, 토큰화(Tokenization)는 필수적이지 않으며, MAE는 픽셀 기반 복원으로 충분한 성능을 냄.