[2025-1] 김학선 - DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence
Introduction
LLMs의 급속한 발전으로 인해 소프트웨어 개발 분야는 크게 변화했다. 그러나 이러한 발전에도 불구하고 LLMs의 주요 도전 과제는 오픈 소스 모델과 폐쇄형 소스 모델간의 성능 격차이다. 강력한 폐쇄형 소스 모델들은 외부의 접근이 제한되며, 독점적인 성격으로 인해 활용에 제약이 따른다. 이러한 도전 과제에 대응하기 위해 DeepSeek-Coder 시리즈를 제시했다.
DeepSeek-Coder 시리즈
- Size: 1.3B ~ 33B
- Version: Base, Instruct
- Pre-train data: Repository 수준에서의 학습 데이터를 구성(→ 교차 파일 이해 능력 향상)
- Pre-train process
- Loss: Next token prediction
- Method: Fill-In-the-Middle(FIM)
- Experiment: 다양한 공개 코드 관련 Benchmark를 활용한 포괄적인 실험 수행
Data Collection
DeepSeek-Coder의 학습 데이터셋은 소스 코드(87%), 코드 관련 영어 자연어 코퍼스(10%), 코드와 무관한 중국어 자연어 코퍼스(3%)로 구성되어 있다.
영어 코퍼스
- GitHub의 Markdown 및 StackExchange에서 수집된 자료로 구성
- 모델이 코드 관련 개념을 이해하고 라이브러리 사용이나 버그 수정과 같은 작업을 더 잘 처리할 수 있도록 돕는다.
중국어 코퍼스
- 고품질 기사로 구성
- 모델의 중국어 이해 능력을 향상시키는 목적
코드 학습 데이터 구성 단계는 아래 Figure 2와 같다.

GitHub Data Crawling and Filtering
GitHub 데이터는 2023년 2월 이전에 생성된 공개 Repository에서 데이터를 수집하고, 87개의 프로그래밍 언어를 기준으로 데이터셋을 구성했다.(Table 1) 이후 데이터 처리량을 줄이기 위해 StarCoder 프로젝트에서 사용된 필터링 규칙과 유사한 방식을 적용하여 저품질 코드를 사전에 필터링했다. 이를 통해 전체 데이터의 크기가 원래의 32.8% 수준으로 감소했다.
StarCoder 프로젝트에서 사용된 필터링 규칙
- Line 길이 필터링: 평균 line 길이 100자 초과하거나 최대 line 길이가 1,000자를 넘는 파일 제거
- 알파벳 문자 비율 필터링: 알파벳 문자 비율이 25% 미만인 파일 제거
- XML 기반 필터링: XSLT 프로그래밍 언어 제외, 문자열 <?xml version=이 파일의 처음 100자 내에 포함된 파일 제거
- HTML 파일 필터링: HTML 코드에서 가시적 텍스트의 비율이 최소 20% 이상이며 텍스트가 100자 이상인 파일만 유지
- JSON 및 YAML 파일 필터링: JSON과 YAML 파일은 문자 수가 50-5,000자 사이인 경우에만 유지

Dependency Parsing
LLM이 파일 단위 소스 코드로 사전 학습되는 방식은 프로젝트 내 서로 다른 파일 간의 의존성을 무시하는 문제가 있다. 따라서 같은 Repository 내 파일들 간의 의존성을 활용하는 방법을 고려했다. 의존성 활용 절차는 다음과 같다.
- 파일 간 의존성 파싱:
→ 파일 간의 호출 관계를 파싱하여 각 파일이 의존하는 맥락이 그 파일 앞에 배치되도록 순서를 정한다. - 의존성 기반 정렬
→ 파일들을 의존성에 따라 정렬하여 실제 코딩 방식과 구조를 더 정확히 반영하도록 데이터셋을 구성한다.
이러한 정렬을 통해 데이터셋의 실질적 활용성과 모델의 프로젝트 수준 코드 처리 능력을 향상시키는데 기여한다. 또한 파일 간 호출 관계만 고려하며, 다음과 같은 정규 표현식을 사용하여 의존성을 추출했다.(ex. Python: import, C#: using, C: include)
의존성 분석을 위한 Topological Sort 알고리즘은 다음과 같다.

Repo-Level Deduplication
최근 연구들에서 LLM의 학습 데이터셋에서 중복 제거가 성능 향상에 중요한 역할을 한다는 것을 입증했다. 여기선 기존 연구완 다른 유사 중복 제거(near-deduplication)를 적용했다.
유사 중복 제거의 기존 방식과의 차이점
- Repository 수준 중복 제거
→ 기존 연구들의 파일 수준의 중복 제거는 Repository 내 특정 파일이 제거되어 Repository 구조가 깨질 위험이 있다. - Repository 구조 유지(무결성 유지)
→ Repository의 모든 코드를 하나의 샘플로 취급하여 저장소 단위로 연결된 코드에 대해 동일한 유사 중복 제거 알고리즘을 적용했다.
Quality Screening and Decontamination
앞서 설명한 필터링 외에도 컴파일러와 품질 모델을 사용하여 저품질 데이터(구문 오류, 가독성 부족, 저조한 모듈화 등을 포함) 필터링을 수행한다. 또한, GitHub에 있는 테스트 셋 정보가 학습 데이터에 오염되지 않도록 n-gram 필터링 과정을 구현했다. 이 과정은 특정 조건에 맞는 코드 세그먼트를 제거하는 방식으로, 구체적인 규칙은 다음과 같다.
- 테스트 셋에서 유래된 코드 제거
→ docstring(설명 주석), 질문, 해결책이 포함된 파일을 필터링 - 10-gram 필터링
→ 10-gram 문자열이 테스트 데이터와 동일한 코드 조각이 포함된 학습 데이터에서 제외한다. - 3-gram 에서 9-gram 사이의 정확한 일치 필터링
→ 테스트 데이터에 있는 3-gram 에서 9-gram 사이의 문자열이 포함된 코드 세그먼트는 정확한 일치 방식을 적용하여 필터링한다.
Training Policy
Training Strategy
Next Token Prediction
Next Token Prediction 과정에서는 여러 개의 파일을 연결하여 고정된 길이의 항목(entry)을 만든다. 그 다음 이 항목들을 모델 학습에 사용하여, 제공된 문맥을 바탕으로 모델이 다음에 올 토큰을 예측할 수 있도록 한다.
Fill-in-the-Middle
코드 사전 학습 시나리오에서는 주어진 문맥과 후속 텍스트를 기반으로, 코드 특정 부분을 적절하게 보완하는 기능이 필요하다. 하지만 프로그래밍 언어의 문법적 구조와 코드 의존성 때문에, 다음 토큰 예측만으로는 이러한 기능을 학습하기 부족하다. 이를 해결하기 위해 Fill-In-the-Middle(FIM) 사전 학습 방법이 제안되었다.
FIM 방식은 텍스트를 무작위 세 부분으로 나누고, 그 순서를 섞은 후 특수 문자로 연결하는 방법으로, 학습 과정에서 빈칸 채우기 형태의 사전 학습 작업을 포함하는 것을 목표로한다. FIM 방법론의 두가지 방식은 다음과 같다.
- PSM (Prefix-Suffix-Middle) mode
→ 학습 코퍼스가 Prefix, Suffix, Middle 순서로 세그먼트를 배열한다. 이후, PSM을 통해 정렬되면 Middle이 Prefix와 Suffix에 의해 둘러싸인 형태로 텍스트를 정렬한다. - SPM (Suffix-Prefix-Middle) mode
→ 학습 코퍼스가 Suffix, Prefix, Middle 순서로 세그먼트를 배열한다. 이후, SPM을 통해 정렬되면 PSM과 같은 형식으로 정렬된다.
위 두 가지 방법은 모델이 코드 내 다양한 구조적 배열을 처리하는 능력을 강화하는데 중요한 역할을 하며, 고급 코드 예측 작업을 위한 견고한 학습 프레임워크를 제공한다.
실험
DeepSeek-Corder-Base 1.3B 모델을 사용하고, Python 하위 집합만을 사용하여 실험을 단순화하여 HumanEval-FIM 벤치마크를 사용한 FIM 기법의 효율성을 평가하는 것을 목표로 한다. 이를 위해 PSM Mode가 기존 다음 토큰 예측 목표와 비교하여 미묘한 차이를 보일 수 있다는 가설을 세우고, 이를 4가지 구성으로 실험했다.
- 0% FIM 비율
- 50% FIM 비율
- 100% FIM 비율
- 50% MSP(Masked Span Prediction) 비율
결과
→ 이건 아무리 봐도 이해가 안되서 뒤에꺼 먼저 하고서 정리할 예정!
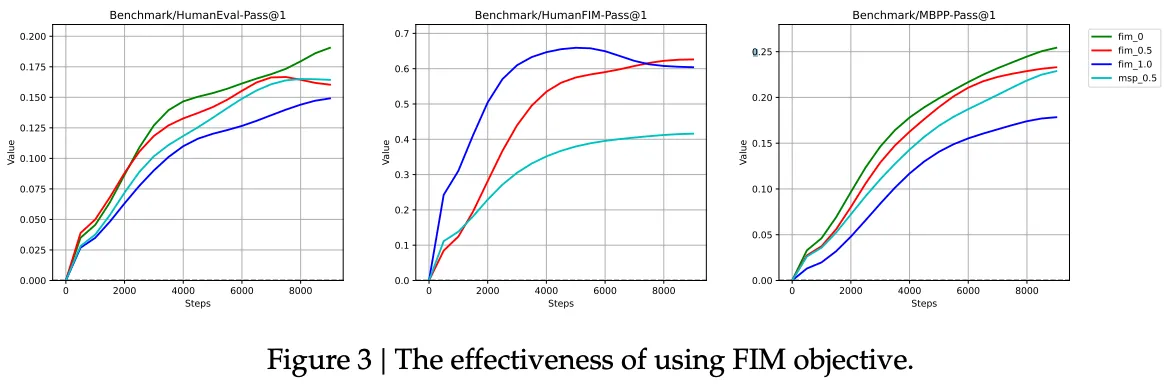
구현
위 작업을 위해 세 개의 특별한 토큰을 도입하여 각 코드 파일을 세 부분으로 나눈다.: $f_{pre}$, $f_{middle}$, $f_{su}$, f.PSM 모드를 사용하여 학습 예제를 다음과 같이 구성한다.
$$<|fim\_start|>f_{pre}<|fim\_hole|>f_{su} f<|fim\_end|> f_{middle}<|eos\_token|>$$
FIM 방법 구현 및 PSM 모드로 FIM 비율을 0.5로 설정하여 진행한다.
Tokenizer
HuggingFace Tokenizer 라이브러리를 사용하여 Byte Pair Encoding(BPE) Tokenizer를 훈련한다. 훈련은 Sennrich et al.(2015)에서 제시된 방법에 따라, 훈련 코퍼스의 하위 집합을 사용하여 BPE Tokenizer를 학습시키고, 최종적으로 어휘 크기가 32,000인 Tokenizer를 사용한다.
Model Architecture
DeepSeek-Coder 시리즈의 각 모델은 디코더 전용 Transformer로, Rotary Position Embedding(RoPE)을 통합하여 구현한다. 특히, DeepSeek-Coder 33B 모델은 Grouped-Query-Attention(GQA)을 통합하여 그룹 크기를 8로 설정하여 훈련과 추론의 효율성을 향상시켰다. 또한, FlashAttention v2를 사용하여 어텐션 메커니즘에서의 계산 속도를 높였다. 모델의 아키텍처 세부 사항은 Table 2에 요약되어 있다.

Optimization
DeepSeek LLM(DeepSeek-AI,2024)에 따라, AdamW를 옵티마이저로 사용, $\beta1$과 $\beta2$ 값은 각각 0.9 0.95로 설정하고, 배치 크기와 학습률은 DeepSeek LLM에서 제시된 스케일링 법칙에 맞춰 조정한다. 학습률 스케일링은 세 단계로 이루어진 정책을 구현한다.(+200번의 워밍업 단계) 마지막으로 최종 학습률은 초기 학습률의 10%로 설정된다.
Environments
실험은 HAI-LLM 프레임워크를 사용하여 진행한다. 이 프레임워크는 LLM 학습에서 효율적이고 가벼운 접근 방식을 제공하며 계산 효율성을 최적화하기 위해 다양한 병렬화 전략을 포함한다.
이 프레임워크에서 실험은 NVIDIA A100과 H800 GPU가 장착된 클러스터에서 진행된다. A100 클러스터에서는 각 노드가 8개의 GPU로 구성 및 LVLink Bridge를 통해 쌍으로 연결되어있다. H800 클러스터 역시 각 노드에 8개의 GPU를 배치하고, NVLink와 LVSwitch 기술을 조합하여 GPU 간 효율적인 데이터 전송을 보장한다. 또한 두 클러스터에서 노드 간 원활한 통신을 위해 InfiniBand Interconnecty를 사용하여 높은 처리량과 낮은 대기시간을 제공한다.
Long Context
DeepSeek-Coderdml 확장된 콘텍스트 처리 능력을 향상시키기 위해, Repository 수준의 코드 처리와 같은 시나리오에서 RoPE 파라미터를 재구성하여 기본 콘텍스트 창을 확장했다. 이전 연구들을 따라 선형 스케일링 전략을 사용하며 스케일링 팩터(1 → 4), 기본 주파수(10,000 → 100,000)을 변경했다. 모델은 배치 크기 512와 시퀸스 길이 16K로 추가적인 1,000 스텝 훈련을 진행했으며, 최종 pre-traininig 단계에서와 동일하게 유지되었다. 실험 결과, 모델은 16K 토큰 범위 내에서 가장 신뢰할 수 있는 출력을 제공하는 것으로 나타났다.
Instruction Tuning
DeepSeek-Coder-Instruct는 DeepSeek-Coder-Base에서 고품질 데이터를 사용하여 명령 기반의 Fine-Tuning을 통해 개발되었다. 각 대화 턴을 구분하기 위해, 각 세그먼트의 끝을 나타내는 고유한 구분자 토큰 <|EOT|> 를 사용했다. 훈련을 위해 100개의 워밍업 스텝을 포함한 코사인 스케줄을 사용하고, 초기 학습률은 1e-5로 설정, 배치 크기는 4M 토큰, 총 2B 토큰을 사용한다.
DeepSeek-Coder-Instruct 34B를 사용하는 예시(Figure 4)를 보면 이 모델이 다중 턴 대화 설정에서 완전한 해결책을 제공할 수 있는 능력을 보여준다.

Experimental Results
DeepSeek-Coder를 코드 생성, FIM 코드 완성, 크로스 파일 코드 완성, 프로그램 기반 수학 추론, 이 네 가지 작업에 대해 이전의 최첨단 LLMs(CodeGeeX2, StarCoder, CodeLlama, code-cushman-001, GPT-3.5와 GPT-4)과 비교한다.
Code Generation
HumanEval and MBPP Benchmark
- HumanEval: 164개의 손으로 작성된 Python 문제로 구성, 테스트 케이스를 사용해 LLM이 생성한 코드를 0-shot setting에서 평가
- MBPP: 500개의 문제를 포함하고 있으며, n-shot setting에서 평가
모델의 다국어 능력을 평가하기 위해, HumanEval의 Python 문제들을 C++, Java, PHP, TypeScript(TS), C#, Bash, JavaScript(JS) 이렇게 7개의 프로그래밍 언어로 확장했다.
두 Benchmark 모두 동일한 스크립트와 환경을 사용하여 기본 결과를 재구현하고 탐욕적인 검색 방식으로 평가를 진행했고, 그에 대한 결과를 Table 3에서 볼 수 있다.

DS-1000 Benchmark
DS-1000 Benchmark는 Matplotlib, NumPy, Pandas, SciPy, Scikit Learn, PyTorch, TensorFlow 7개의 서로 다른 라이브러리에서 1,000개의 실제적이고 실용적인 DataScience Workflow를 포함한 포괄적인 데이터 셋을 제공한다. 이 Benchmark는 특정 테스트 케이스에 대해 실행하여 코드 생성을 평가하고, 문제를 라이브러리에 따라 분류하고 있다는 특징이 있다. 추가적으로 코드 완성 설정에서 기본 모델의 성능을 평가하며, 각 라이브러리별 pass@1 결과와 전체 점수를 제공한다. 이 Benchmark의 결과는 Table 4에서 볼 수 있다.

LeetCode Contest Benchmark
모델의 실제 프로그래밍 문제 해결 능력을 추가 검증하기 위해 LeetCode Contest Benchmark를 구축했다. LeetCode Contest에서 최신 문제를 수집하여, 사전 훈련 데이터에 문제가 포함되거나 그 솔루션이 등장하지 않도록 했다. 2023년 7월부터 2024년 1월까지 총 180개의 문제, 그리고 각 문제에 대해 100개의 테스트 케이스를 수집하여 테스트 범위를 보장했다. 문제 설명을 바탕으로 python\n{code_template}\n 형식의 지시문을 작성하여 평가를 진행했고, 평가 결과는 Table 5에서 볼 수 있다.
여기서 기본 모델에 Chain-of-Thought(CoT) 프롬프트를 구현한 모델들의 결과를 보면 대부분의 경우에서 모델의 능력이 향상되는 것을 볼 수 있는데, 이를 통해 복잡한 코드 과제의 경우 CoT 프롬프트 전략을 사용하는 것이 좋다는 것을 볼 수 있다.

FIM Code Completion
DeepSeek-Coder 모델은 사전 훈련 단계에서 0.5 FIM 비율로 훈련되어 prefix와 suffix의 정보를 바탕으로 공백을 채우는 방식으로 코드 생성 능력을 향상시켜준다. DeepSeek-Coder 모델 성능 평가에서는 코드 자동 완성 도구인 StantaCoder, StarCoder, CodeLlama 모델과의 비교 분석이 이루어졌다. 비교에 사용된 벤치마크는 Single-Line Infilling 벤치마크로, 세 가지 프로그래밍 언어(Python, Java, JavaScript)를 포함하며 Line exact match accuracy를 평가 지표로 사용한다. 이 벤치마크에 대한 결과는 Table 6에 나온다. 이 결과를 통해 코드 완성 작업에서 높은 정확도를 달성하기 위해서는 모델 용량이 중요하다는 것을 강조한다.

Cross-File Code Completion
Cross-File Code Completion은 모델이 Repository와 다양한 파일들 간의 의존성을 이해하고 접근할 수 있어야 한다. 이를 평가하기 위해 CrossCodeEval을 사용했다. 이 데이터셋은 네 가지 인기 있는 프로그래밍 언어(Python, Java, TypeScript, C#)에서 실제 오픈소스 및 자유 라이선스 Repository를 기반으로 구성되었다.
CrossCodeEval 데이터셋은 정확한 코드 완성을 위해 반드시 파일 간 문맥 정보를 요구하도록 설계되었다. 이때 CrossCodeEval 데이터셋과 DeepSeek-Coder의 사전 훈련 데이터셋 간의 데이터 유출이 발생하지 않도록 했다.
여러 모델 평가에서 최대 시퀸스 길이는 2048 토큰, 최대 출력 길이는 50 토큰, 다중 파일 문맥 제한은 512 토큰으로 설정하고, 다중 파일 문맥은 BM25 검색 결과를 활용했다. 평가 지표로는 Exact Match(EM)과 Edit Similarity(ES)를 사용했다. Cross-file code completion에 대한 평가 결과는 Table 7에서 볼 수 있다. 이를 통해 Repo Pre-training이 모델의 성능에 영향을 미치는 것을 볼 수 있다.

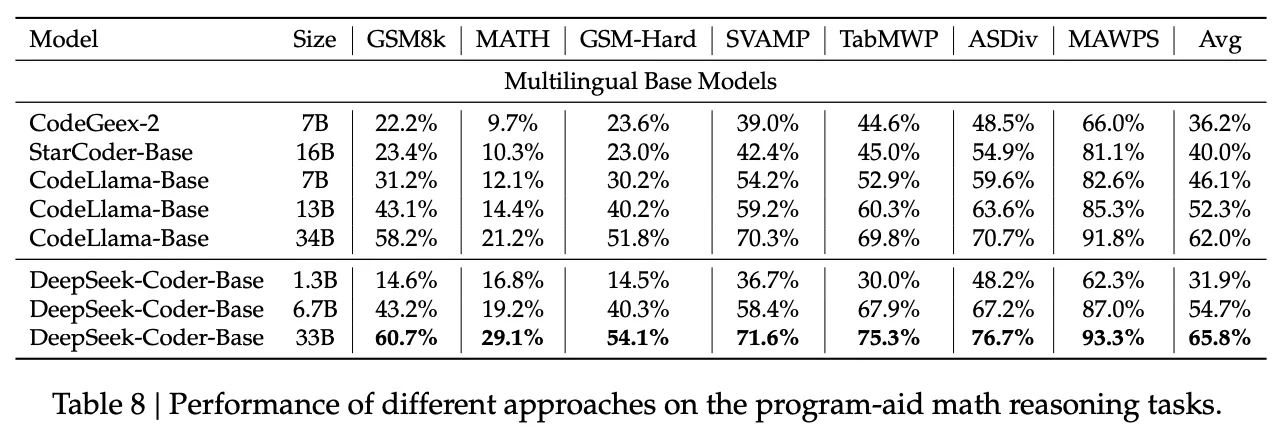
Program-based Math Reasoning
Program-based math reasoning에서의 평가를 위해 Program-Aided Math Reasoning(PAL) 방법을 활용한다. 이 방법을 고유한 7개의 벤치마크에 적용하고, 각 벤치마크에서 모델은 자연어로 해결 단계에 대한 설명을 번갈아 제공한 후 그 단계를 코드로 실행하는 방식으로 테스트된다. 평가 결과는 Table 8에서 볼 수 있다.
Continue Pre-Training From General LLM
DeepSeek-Coder 모델의 자연어 이해 및 수학적 추론 능력을 더욱 강화하기 위해 DeepSeek-LLM-7B Base에 추가적인 Pre-Training을 수행하여 DeepSeek-Coder-v1.5 7B 모델을 개발했다. DeepSeek-Coder-v1.5 7B 모델과 DeepSeek-Coder 6.7B 모델을 비교하기 위해 모든 벤치마크를 동일한 평가 파이프라인으로 재실행하여 공정한 비교를 보장했다. 평가 작업은 다음과 같이 분류했다.
- 프로그래밍: 다국어 설정에서 HumanEval 데이터셋 & Python 설정에서 MBPP 데이터셋
- 수학적 추론: GSM8K & MATH 벤치마크
- 자연어, MMLU, BBH, HellaSwag, Winogrande, ARC-Challenger 등의 벤치마크
DeepSeek-Coder의 Base 및 Instruct 모델의 결과는 Table 10에서 볼 수 있다. 이 경우 DeepSeek-Coder-Base-v1.5 모델은 프로그래밍에서 낮은 성능을 보이지만 수학적 추론과 자연어 처리 부분에서는 뛰어난 성능을 보인다.

Conclusion
코딩에 특화된 LLM인 DeepSeek-Coder 모델들은 프로젝트 수준의 코드 코퍼스를 기반으로 정교하게 학습되었으며, FIM 학습을 통해 코드 채우기 기능을 향상시켰다. 특히 모델의 콘텍스트 윈도우를 확장하여 대규모 코드 생성 작업에서 효율성을 크게 개선했다. DeepSeek-Coder-Base 6.7B 모델은 상대적으로 작은 규모임에도 CodeLlama 34B와 유사한 성능을 기록하여 Pre-Training 코퍼스의 높은 품질을 인증했다.
- DeepSeek-Coder-Instruct 33B:
→ 고품질 supervised data로 FT되어 OpenAI GPT-3.5 Turbo보다 다양한 코딩 관련 작업에서 우수한 성능을 보임 - DeepSeek-Coder-v1.5:
→ DeepSeek-LLM 7B 체크포인트를 기반으로 Pre-Training을 수행하여 코딩 성능은 유지하면서 자연어 이해 능력을 향상시켰다.
결론: 코딩 작업을 효과적으로 해석하고 실행하기 위해 모델은 다양한 형태의 자연어로 제공되는 인간의 지시를 심층적으로 이해할 필요가 있다.