NLP
[2025-1] 정유림 - SimCSE: Simple Contrastive Learning of Sentence Embeddings
urmu
2025. 2. 8. 18:43
1. 논문 개요
- 논문 제목: SimCSE: Simple Contrastive Learning of Sentence Embeddings
- 게재 연도: 2021 (EMNLP 2021 Accepted)
- 인용 횟수: 3449회 (2025.02.08 기준)
- 주요 성과:
- SimCSE는 간단한 대조 학습(Contrastive Learning) 프레임워크로 기존 문장 임베딩(Sentence Embedding) 성능을 획기적으로 개선.
- 비지도 학습(Unsupervised): 입력 문장을 두 번 인코딩하여 드롭아웃(Dropout) 노이즈로 양성 쌍 생성.
- 지도 학습(Supervised): NLI 데이터셋의 Entailment 쌍(Positive Pair)과 Contradiction 쌍(Hard Negative Pair) 활용.
- 평가 결과:
- Unsupervised SimCSE (BERT base): 76.3% Spearman's 상관계수 (기존 대비 +4.2% 향상)
- Supervised SimCSE (BERT base): 81.6% Spearman's 상관계수 (기존 대비 +2.2% 향상)
- 이론적·실험적 분석: 대조 학습이 임베딩의 비등방성(Anisotropy) 문제를 완화하고, 균일성(Uniformity)과 정렬성(Alignment) 개선.
- DOI: arXiv:2104.08821
2. 연구 배경
- 대조 학습(Contrastive Learning):
- Positive Pair: 의미적으로 유사한 문장 쌍을 가깝게 학습.
- Negative Pair: 유사하지 않은 문장 쌍을 멀리 학습

- 손실 함수 (Contrastive Loss):
- 분자: Positive Pair의 유사도를 최대화.
- 분모: 배치 내 Negative Pair를 최소화.
- Positive Pair 생성 방법:
- 컴퓨터 비전(CV): 이미지 변형(Augmentation) 기법 활용.
- 자연어 처리(NLP): 데이터 증강(Data Augmentation) 기법 활용 (단어 삭제, 재배열, 대체 등).
- in SimCSE : 드롭아웃(Dropout) 노이즈를 양성 쌍 생성에 활용 : 같은 문장을 두 번 인코딩하되, 다른 드롭아웃 마스크를 적용 → 의미는 같지만 임베딩은 다르게 만들어 양성 쌍 구성
(참고) Dropout : 같은 encoder이지만, encoder에 일부 뉴런을 비활성화한다는 개념
(신경망에서 일부 뉴런(노드)을 임의로 비활성화(0으로 설정)하는 정규화 기법)
3. Unsupervised SimCSE
- 핵심 개념: 같은 문장을 두 번 인코딩하고, 드롭아웃을 적용하여 Positive Pair 생성.

- 데이터 증강 비교 (Table 1): 드롭아웃만 적용한 SimCSE가 최고 성능.

- 비지도 학습 방법 비교 (Table 2): SimCSE가 기존 방식보다 높은 성능.

- 드롭아웃 확률 변화 (Table 3): p=0.1일 때 최적의 성능.

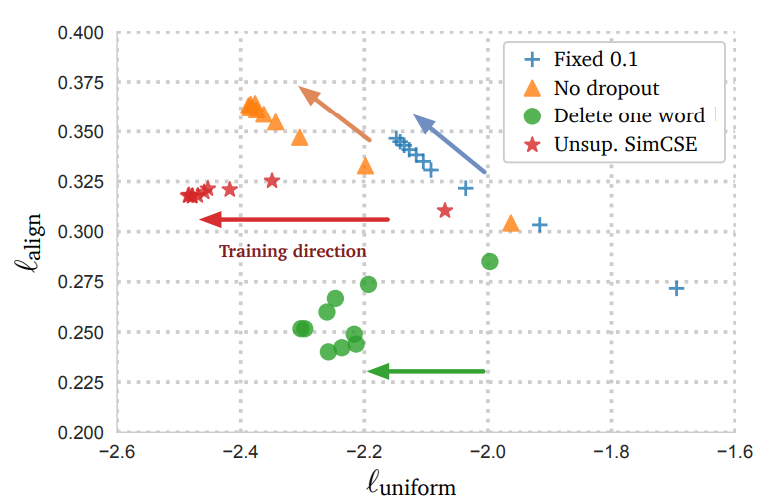
- (Figure 2) Unsupervised SimCSE (드롭아웃 적용)에서 학습이 진행될수록 임베딩이 더 고르게 분포하고, 양성 쌍은 더 가깝게 유지됨
4. Supervised SimCSE

- 지도 학습 데이터: NLI 데이터셋 (SNLI + MNLI) 활용.
- Positive Pair: Entailment 쌍.
- Hard Negative Pair: Contradiction 쌍.
- 손실 함수: Positive Pair는 최대화, Hard Negative는 최소화.

- 학습 데이터셋 비교 (Table 4): Hard Negative 추가 시 성능 향상.

5. Connection to Anisotropy
- 비등방성(Anisotropy) 문제: 임베딩이 특정 방향으로 치우치는 현상.
- SimCSE의 개선: 대조 학습으로 비등방성 완화 및 임베딩의 균일성(Uniformity) 개선.
6. Experiment
- 평가 데이터셋: 7개의 STS 과제와 7개의 전이 학습 과제.
- 결과 (Table 5): SimCSE가 기존 모델보다 월등한 성능.

- Pooling 방법 비교 (Table 6): 비지도 학습에서는 CLS + MLP(Train only) 최적.

- Hard Negative 효과 (Table 7): Contradiction 쌍 활용 시 성능 향상, alpha(가중치)가 1.0일때 가장 좋은 성능.

7-1. Uniformity & Alignment 분석

- 균일성(Uniformity): 임베딩이 얼마나 고르게 분포하는지 평가.
- 정렬성(Alignment): 의미적으로 유사한 문장 쌍이 얼마나 가깝게 위치하는지 평가.
- 결과: Supervised SimCSE가 가장 높은 균일성 및 정렬성을 유지하며 최고 성능 기록.
7-2. Qualitative comparison : SimCSE-BERTbase가 SBERTbase보다 더 높은 품질의 문장 검색 성능 기록.
8. 결론
- SimCSE는 간단한 대조 학습 프레임워크로 기존 문장 임베딩 방법보다 높은 성능을 달성.
- 비지도 학습과 지도 학습 모두에서 강력한 성능 입증.
- 대조 학습의 이론적 기여: 임베딩의 비등방성(anisotropic) 문제 해결 및 표현력 향상.