[2025-1] 황징아이 - Temporal Feature Alignment and Mutual Information Maximization for Video-Based Human Pose Estimation
논문 : https://arxiv.org/abs/2203.15227
코드 : https://github.com/Pose-Group/FAMI-Pose
GitHub - Pose-Group/FAMI-Pose: This is an official implementation of our CVPR 2022 ORAL paper "Temporal Feature Alignment and Mu
This is an official implementation of our CVPR 2022 ORAL paper "Temporal Feature Alignment and Mutual Information Maximization for Video-Based Human Pose Estimation" . - Pose-Group/FAMI-Pose
github.com
CVPR 2022년 Pose Estimation 논문
1. Introduction
영상 기반 자세 추정은 컴퓨터 비전에서 행동 인식(Action Recognition), 증강 현실(AR), 감시(Surveillance), 스포츠 분석 등 다양한 응용 분야에서 필수적인 기술이다. 그러나 비디오 프레임 간의 움직임과 포즈 가림(occlusion) 문제로 인해, 단일 이미지 기반 방법보다 훨씬 더 높은 난도를 가진다.
기존 연구들은 이러한 문제를 해결하기 위해 이웃 프레임의 정보를 활용하는 방식으로 접근해 왔다. 하지만 대부분의 기존 방법들은 프레임 간 특징을 정렬하지 않고 단순히 정보를 결합하는 방식이어서, 효과적으로 정보를 활용하는 데 한계가 있다.
이 논문에서는 이러한 문제를 해결하기 위해 FAMI-Pose (Feature Alignment and Mutual Information Maximization for Pose Estimation)을 제안한다.
- Hierarchical Alignment Framework를 도입하여 프레임 간 특징을 효과적으로 정렬
- Mutual Information (MI) Loss를 적용해 이웃 프레임에서 유용한 정보만 학습하도록 유도
2. Related Work
이미지 기반 자세추정
기존 연구에서 이미지 기반 자세추정은 Bottom-up vs Top-down 접근법으로 나뉜다.
- Bottom-up: 개별 신체 부위를 먼저 검출한 뒤, 이를 조합해 전체 포즈를 구성 (예: OpenPose, HRNet)
- Top-down: 사람을 먼저 감지한 후 해당 영역에서 자세 예측 (예: SimpleBaseline, HRNet)
- 한계 : 프레임 간 시간적 관계를 고려하지 않는다
영상 기반 자세추정
- 순차적 특징 집계(Sequential Feature Aggregation)
- CNN + LSTM 구조로 시간적 관계를 학습 (예: PoseLSTM, Temporal Convolution Networks)
- 한계 : 프레임 간 특징 정렬을 고려하지 않아 빠른 움직임에서 성능 저하
- 광학 흐름(Optical Flow) 기반 정렬
- Optical Flow를 활용해 프레임 간 이동을 보정 (예: DCPose, PoseWarper)
- 한계 : 광학 흐름의 부정확성이 자세 예측 성능을 저하
특징 정렬(Feature Alignment)
- 객체 감지, 이미지 분할에서는 FPN(Feature Pyramid Networks) 등 다양한 정렬 방법이 연구되었으나 시간적 정렬(temporal alignment)을 적용한 연구는 부족한 상황
3. Method
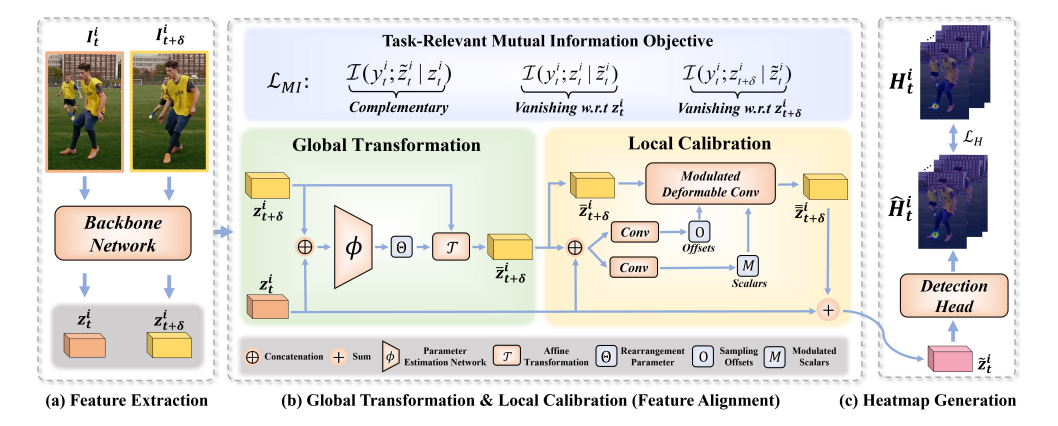
- Feature Extraction
주어진 비디오에서 특정 순간의 키 프레임 $I_t^i$ (왼쪽 이미지)과, 그와 가까운 시간대의 지원 프레임 $I_{t+\delta}^i$ (오른쪽 이미지)를 입력으로 사용하고 Backbone Network을 통해 두 프레임의 특징을 추출하게 됩니다. $(z_t^i, z_{t+\delta}^i)$ - Global Transformation + Local Calibration (Feature Alignment)
-
- Global Transformation : 특징을 정렬하기 위해 Affine Transformation 파라미터를 추정하여 $\bar {z}_{t+\delta}^i$를 얻는다
- Local Calibration : 픽셀 단위 변형(Pixelwise Deformation)을 수행하여 $\bar {\bar {z}}_{t+\delta}^i$를 얻는다
- 모든 특징 $\bar {\bar {z}}_{t+\delta}^i$ 와 키 프레임의 특징 $z_t^i$를 합쳐서 $\tilde {z}_t^i$ 를 얻는다
-
- Heatmap Generation
$\tilde {z}_t^i$ 는 Detection Head로 전달되어 $\hat H^i_t$를 생성
Mutual Information Objective
- 히트맵 추정 손실(Heatmap Estimation Loss) $L_H$최소화
- 예측된 히트맵 $\hat H^t$ 와 실제 정답 히트맵 $H_t$ 간의 차이를 줄이는 것을 목표로 함
- 향상된 특징 $\tilde {z}_t$ 에 포함된 보완적이고 과업-관련된 정보 최대화
- Mutual Information Objective $L_{MI}$ 를 적용하여, 이웃 프레임에서 얻을 수 있는 유용한 정보를 최대한 활용하도록 유도.
4. Global Transformation Module (GTM)
빠르게 움직이는 객체(사람)나 카메라 이동이 있는 경우, 같은 사람이라도 다른 위치에서 관측될 수 있기 때문에 자세 추정 모델이 특정 프레임(key frame)과 이웃 프레임(supporting frames) 간의 전반적인 공간 이동(spatial shift)을 보정해야 한다.
- Affine Transformation의 변환 파라미터 $\Theta$을 학습 : 이웃 프레임을 키프레임과 정렬할 수 있도록 함
$$ \Theta=\phi\left(z_t^i, z_{t+\delta}^i\right) $$
-
- $\phi$ : 학습하는 변환함수
- $z_t^i$ : key frame의 특징
- $z_{t+\delta}^i$ : supporting frame의 특징
- Affine Transformation 적용 : 학습한 변환 파라미터를 이용해 지원 프레임을 정렬
$$ \bar z^i_{t+\delta} = T(z^i_{t+\delta}, \Theta) $$
- $T$ : Affine 변환 적용
- $\bar z^i_{t+\delta}$ : 변환 후 정렬된 지원 프레임의 특징
결과적으로, Global Transformation을 통해 위치를 보정해서 특징들을 정렬
5. Local Calibration Module (LCM)

- Global Transformation 후에도 사소한 변형(미세한 움직임, 포즈 차이)이 남아 있을 수 있어서 Modulated Deformable Convolution을 사용하여 픽셀 단위로 조정하고 최종적으로 정확히 정렬된 특징 $\tilde {z}_{t+\delta}^i$를 생성
- Deformable Convolution을 활용하여 픽셀 단위 위치 조정(offset learning) 및 강도 조절(scale modulation). 기존 CNN과 달리 고정된 필터 크기가 아니라 픽셀별로 유연하게 위치를 조정하면서 특정 영역이 더 중요한 경우 해당 픽셀의 특징을 강조
- 결과적으로, Global Transformation + Local Calibration을 통해 보다 정밀한 특징 정렬을 달성
6. Mutual Information Maximization Loss
기존 자세 추정 모델들은 보통 Mean Squared Error (MSE) 손실을 사용하여 학습하지만, 이는 단순히 예측 결과와 정답 간의 차이를 줄이는 방식이기 때문에 이웃 프레임의 유용한 정보 활용을 보장하지 않는다. FAMI-Pose는 Mutual Information Maximization Loss를 도입하여 프레임 간 의미 있는 정보를 더 효과적으로 추출하도록 설계함.
- Mutual Information 최대화 : 프레임간의 유용한 정보를 더 많이 유지하도록 학습

- ML Loss 최소화 : 기존 MSE 기반 히트맵 손실을 포함하여, 예측된 히트맵 \hat {H}_t^i와 정답 히트맵 H_t^i 간의 차이를 최소화

- 최종 Loss 계산 : 보완적 정보(Complementary Information) 학습하고 기존 프레임과 이웃 프레임 간 정보 중복을 줄이고, 필요한 정보만 유지
- 전체 손실 함수: MSE 손실 + Mutual Information 손실 조합
- $$\beta=0.1$로 가중치를 조정하여 학습


→ 최적화 목표 : 이웃 프레임에서 유용한 정보는 유지하되 불필요한 중복 정보는 제거한다
7. Experimental Settings
- Dataset : PoseTrack 2017, PoseTrack 2018, Sub-JHMDB
- Input Image: 384 x 288
- Data Augmentation : Random Rotation, Random Scaling, Random Truncation, Horizontal Flipping
- Optimizer : Adam (1e-4)
8. Result
- Coarse-to-Fine 방식의 계층적 정렬을 통해 이웃 프레임을 효과적으로 정렬
- Mutual Information Loss를 도입하여 불필요한 정보는 제거하고 유용한 정보만 유지
- 기존 SOTA 모델들보다 뛰어난 성능 달성 (PoseTrack2017, 2018, Sub-JHMDB 모두 개선)
- 결과적으로, FAMI-Pose는 빠른 움직임과 포즈 가림이 많은 상황에서도 좋은 자세 추정 성능을 보였다