[2025-1] 김은서 - Direct Preference Optimization: Your Language Model is Secretly a Reward Model (2023)
Direct Preference Optimization: Your Language Model is Secretly a...
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining s
arxiv.org
Introduction

LLM을 조정하는 기존의 방법은 RL(강화학습)이다. 이때, LLM 모델에 선호도 학습을 포함함으로서 성능이 뛰어난 AI 시스템을 구축할 수 있다. 선호도 학습의 가장 성공적인 방법은 RLHF이다. 하지만 RLHF는 여러 LM 학습과 LM policy sampling 등에서 상당한 계산 비용이 발생한다는 문제가 있다. 따라서 본 논문에서는 명시적인 reward modeling과 RL 없이 인간의 선호도에 맞추어 LM을 최적화하는 방법을 제시하는데, 그 방법이 바로 DPO다.
RLHF

1단계: Supervied fine-tuning (SFT)
- 이전에 학습된 LM을 fine-tuning한다
- fine-tuning된 모델 $\pi^{SFT}$을 얻는다
2단계: Reward Modelling Phase

- x를 input이라고 생각하면, $y_{1}$과 $y_{2}$는 SFT 모델이 생성한 output이다
- 인간에 의해 $y_{1}$과 $y_{2}$ 사이에서 선호가 표현된다 (이때, 선호하는 답은 $y_{w}$, 선호하지 않는 답을 $y_{l}$라고 하자)
- 선호도는 접근할 수 없는 어떤 latent reward model $r^*(x,y)$에 의해 생성된 것으로 가정하자
- 여기에서는 $r$을 정의하는데 BT model이 사용되었다
negative log-likelihood loss는 다음과 같고, 이를 이용하여 Reward Model을 학습시킨다.

3단계: RL Fine-Tuning Phase
이 단계에서는 학습된 reward function을 사용하여 LM에 피드백을 제공한다. 사용되는 optimization은 다음과 같다.

reward는 다음과 같고,

이 reward를 maximize하기 위해 PPO를 사용한다. 따라서 PPO로 최적의 정책 $π _{θ} (y|x)$을 학습하는 것이다.
핵심은 RLHF는 reward model을 학습하고, 그 다음 PPO로 $π _{θ} (y|x)$를 학습한다는 것이다.
DPO
DPO 유도

DPO의 loss function은 위와 같다. 위의 함수를 얻기 위한 과정은 다음과 같다.
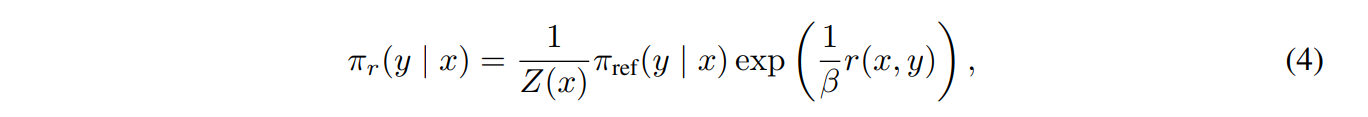
(4)는 optimal policy에 대한 수식이다. (4) 수식에서, reward 함수를 좌변에 두고 식을 정리하면

(5) 수식이 나온다. 이를 RLHF에서의 (2) 수식(RL loss function)에 대입하면 DPO의 loss function을 구할 수 있다.
추가로, (5) 수식을 (1) 수식(RL perference model)의 $r^*$ 자리에 대입하면 다음과 같은 새로운 perference model을 도출할 수 있다.

DPO 업데이트는 무엇을 하는가?
파라미터 θ(weight)에 대한 loss function $L_{DPO}$의 gradient는 다음과 같다.

- $y_{w}$의 likelihood는 높이고, $y_{l}$의 likelihood는 낮추는 방향
- sigmoid function에 의해 weight는 0~1 사이의 값을 갖는다
- $y_{w}$의 reward가 $y_{l}$의 reward 값보다 낮게 측정되면, weight가 1에 가까워진다
따라서 DPO는 선호 데이터를 직접 학습하면서, 선호하는 행동을 더 자주 선택하고, 선호하지 않은 행동을 줄이는 방향으로 정책을 최적화한다.
Experiments

- DPO model이 KL에 independence하게 reward를 주고 있다

- Best of 128과 다른 model을 비교 했을 때, DPO가 가장 비슷하다

- 위의 상황과 마찬가지로 좋은 성능을 보여준다
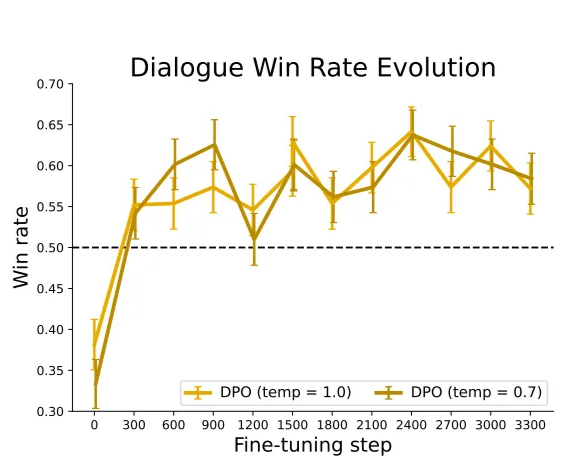
- 다양한 온도 sampling에서도 DPO가 안정적이다
논문에서는 GPT-4의 판단의 신뢰성을 검정하기 위해서 human study를 진행하였다. human study의 결과는 다음과 같다.
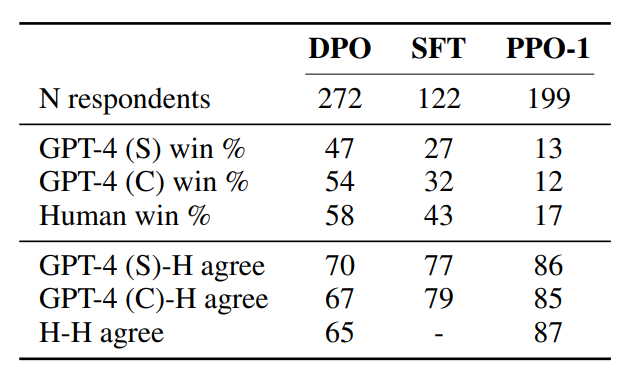
- GPT-4의 판단이 사람의 판단과 강한 상관 관계가 있음을 보여준다
- GPT-4와 사람 사이의 일치율이 사람과 사람 사이의 일치율보다 비슷하거나 높다